A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models
英文题目:《A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models》
中文题目:《大型语言模型中幻觉缓解技术的综合综述》
发布于: arxiv
级别:无
摘要
随着大型语言模型(LLMs)在编写类人文本方面的能力不断提高,一个关键挑战仍然存在,即它们倾向于“幻觉”——生成看起来是事实但没有根据的内容。这种幻觉问题可以说是将这些强大的LLM安全地部署到影响人们生活的真实生产系统中的最大障碍。在实际环境中广泛采用LLM的道路在很大程度上取决于解决和减轻幻觉。与专注于有限任务的传统人工智能系统不同,LLM在训练期间接触了大量的在线文本数据。虽然这使它们能够表现出令人印象深刻的语言流畅性,但也意味着它们能够从训练数据中的偏差中推断信息,误解模糊的提示,或修改信息以使其表面上与输入对齐。当我们依赖语言生成能力进行敏感应用时,例如总结医疗记录、客户支持对话、财务分析报告以及提供错误的法律建议,这变得非常令人担忧。小错误可能会导致伤害,揭示了LLM缺乏实际理解,尽管在自学习方面取得了进展。本文对为减轻LLM中的幻觉而开发的32多种技术进行了全面调查。其中值得注意的是检索增强生成(RAG)(Lewis et al., 2021)、知识检索(Varshney et al., 2023)、CoNLI(Lei et al., 2023)和CoVe(Dhuliawala et al., 2023)。此外,我们引入了一个详细的分类法,根据各种参数(例如数据集利用率、常见任务、反馈机制和检索器类型)对这些方法进行分类。这种分类有助于区分专门设计用于解决LLM中幻觉问题的各种方法。此外,我们分析了这些技术中固有的挑战和局限性,为未来研究解决LLM领域内的幻觉和相关现象提供了坚实的基础。
本文聚焦的问题
本文聚焦的核心问题是大型语言模型(LLMs)的 “幻觉” 现象 —— 即模型生成看似合理但缺乏事实依据的错误内容,这一问题成为阻碍其在医疗记录总结、金融分析、法律建议等敏感领域安全部署的关键障碍。具体而言,文章关注幻觉产生的原因(如训练数据中的偏见、对模糊提示的误解读、缺乏实时信息更新等),并围绕如何系统地缓解这一现象展开,旨在通过梳理现有技术、构建分类体系,为解决幻觉问题提供全面的理论基础和实践指导。
本文提出的方法
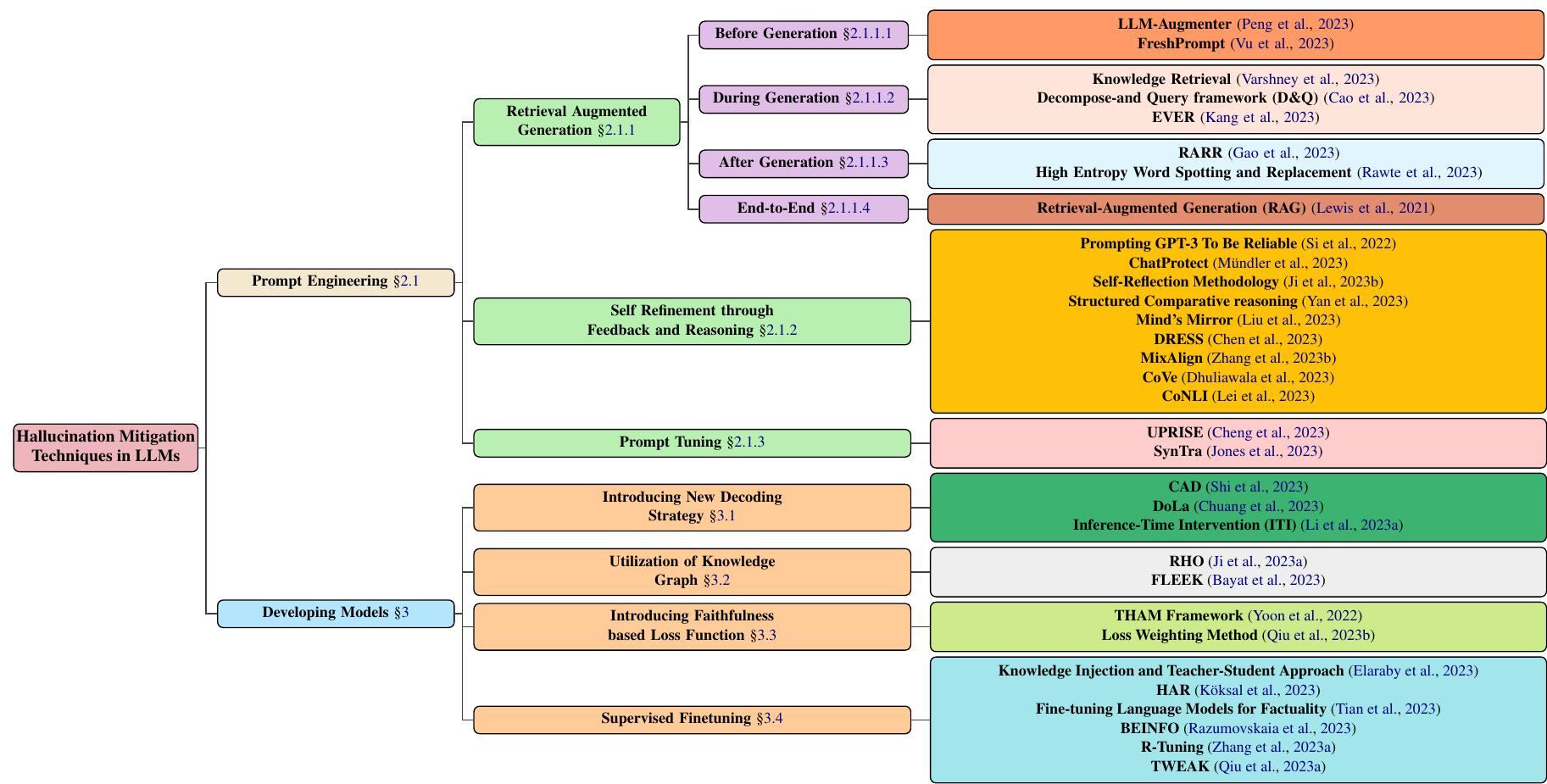
LLM 中幻觉缓解技术的分类,重点介绍涉及模型开发和提示技术的主流方法。模型开发分为多种方法,包括新的解码策略、基于知识图的优化、添加新的损失函数组件以及监督式微调。同时,提示工程可以涉及基于检索增强的方法、基于反馈的策略或提示调整。
Prompt engineering is the process of experimenting with various instructions to get the best output possible from an AI text generation model (White et al., 2023). In terms of hallucination mitigation, this process can provide specific context and expected outcomes (Feldman et al., 2023). The prompt engineering mitigation techniques can be outlined as follows:
一是检索增强生成(RAG),分生成前(借外部模块、动态更新提示增知识)、生成中(实时检测修正、分步检索等)、生成后(依检索证据改输出、换高不确定性词)及端到端 RAG(联合训练检索与生成器);二是自我优化,借反馈推理(像自验证流程、结构化比较等)让模型自查自纠;三是提示调整,靠轻量检索器、合成任务优化提示,提升表现并减少幻觉。
Some papers focused on developing novel models to mitigate hallucinations. It is an ongoing and evolving process requiring a combination of algorithmic advancements and data quality improvements. Instead of going for fine-tuning models, the following techniques implemented whole model architecture to tackle hallucinations. These techniques can be categorized as follows:
新解码策略,借对比分布、干预注意力等增强输出真实性;知识图谱利用,融合实体关系、用自动化工具验证事实;基于忠实度的损失函数,借正则化、指标加权优化训练;监督微调,结合知识注入、反事实数据等,量化并降低幻觉,还能让模型拒答超知识范围问题。
阅读总结
优点:
- 提示工程:灵活,无需改模型架构,快速适配场景;
- 成本低,不重训模型;可快速试错迭代,组合优化策略。
缺点:
- 提示工程:依赖检索质量(如RAG类方法,外部知识库的质量);仅调输入输出,难解决深层幻觉;策略效果不稳定,跨任务和模型差异大。
- 模型开发:计算成本高;开发难,需深入模型架构,易引发新问题;领域适配差,跨领域需重调。