Enhanced Language Model Truthfulness with Learnable Intervention and Uncertainty Expression
英文题目:《Enhanced Language Model Truthfulness with Learnable Intervention and Uncertainty Expression》
中文题目:《通过可学习干预和不确定性表达的增强语言模型真实性》
发布于: arxiv
级别:无
摘要
大语言模型(LLMs)能够生成长篇连贯的文本,但它们常常会产生事实幻觉,这削弱了其可靠性。为缓解这一问题,推理阶段的方法会将大语言模型的表征导向之前为获取真相而学习到的 “真实方向”。然而,以相同强度应用这些真实方向无法在不同的查询上下文之间实现泛化。我们提出了LITO,一种用于真实性优化的可学习干预方法,它能自动识别针对每个特定上下文量身定制的最佳干预强度。LITO基于不断增加的干预强度探索一系列模型生成结果。当预测高度不确定时,它会选择最准确的回答或拒绝回答。在多个大语言模型和问答数据集上进行的实验表明,LITO在保持任务准确性的同时提高了真实性。LITO的自适应特性克服了一刀切干预方法的局限性,仅在模型有信心时通过反映其内部知识来最大限度地提高真实性。我们的代码可在https://github.com/launchnlp/LITO获取。
本文聚焦的问题
本文聚焦的核心问题是大语言模型的“幻觉”现象——即模型生成看似合理但缺乏事实依据的错误内容,尤其针对现有推理时干预方法(如ITI)采用固定强度干预,无法适配不同查询上下文,导致在不同场景中难以有效缓解幻觉,且缺乏合理的不确定性表达机制的局限性,最终目标是提升模型的真实性与可靠性。
本文提出的方法
为解决先前方法中一刀切干预解决方案的局限性,我们提出了一种用于真实性优化的可学习干预方法,即LITO。LITO可识别适合不同上下文(例如不同问题)的真实方向强度。给定多个干预强度级别下的模型生成序列,我们开发了一种方法来最大化真实性,我们将其定义为在模型高度自信时选择事实性回答,否则拒绝回答。为实现这一点,我们在不断增加的干预强度级别上收集模型回答,包括文本输出、隐藏表示和置信度值。然后,我们训练一个基于长短期记忆网络(LSTM)的分类器,根据隐藏状态序列评估这些回答的准确性。在推理过程中,如果分类器认为有任何回答是准确的,系统就选择最准确的回答;否则,它输出“无可奉告”以表示不确定性并拒绝回答。
1.多强度干预与数据收集:基于现有推理时干预方法(如ITI)识别的“真实方向”,在不同强度(如α=5、10、15、20、25)下生成模型对同一问题的响应,同时收集每个响应的文本内容、最后一层隐藏状态及置信度(通过生成序列的token概率几何平均计算)。
2.训练阶段:将多强度响应的隐藏状态聚合后输入LSTM分类器,让其学习判断不同强度下响应的准确性,最终通过全连接层输出事实性概率,从而掌握不同场景下的最优干预规律。
3.推理阶段:对新输入的问题,生成多强度响应后,用训练好的LSTM分类器评估各响应的准确性。若存在准确响应,选择置信度最高的输出;若所有响应均不准确,则输出“我没有评论”以表达不确定性。
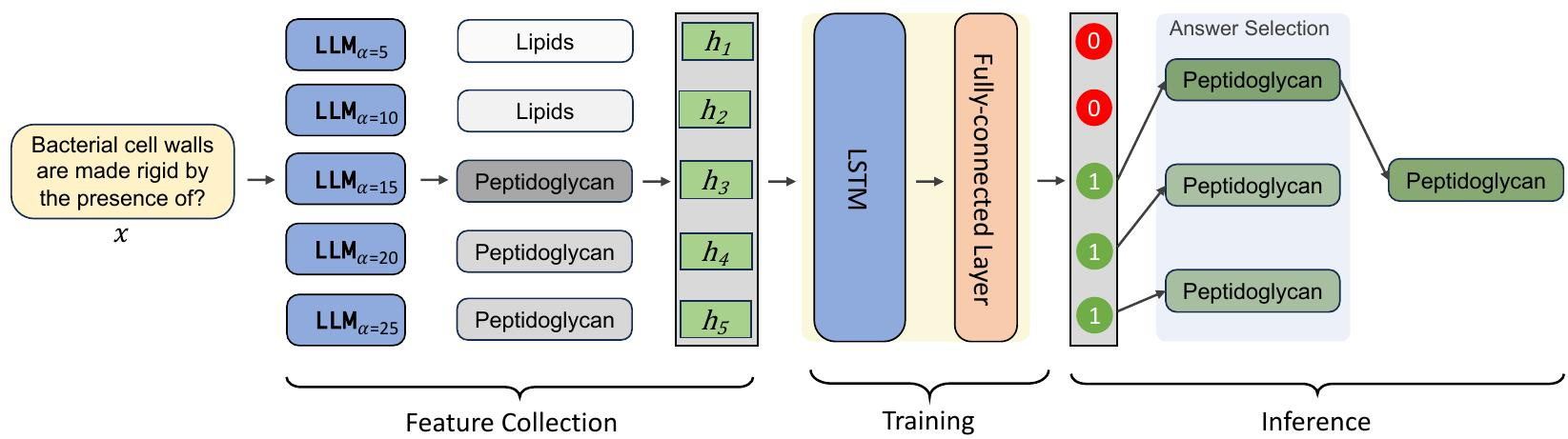
该方法通过动态适配干预强度,解决了现有固定强度干预无法适应不同上下文的问题,同时引入不确定性表达机制,在提升真实性的同时保持了任务准确性。
阅读总结
优点:
- 动态适配性强,能针对不同查询上下文自动选择最优干预强度,平衡真实性与准确性。
- 具备不确定性表达能力,且泛化性较好,可与多种真实方向识别方法结合并稳定跨任务迁移。
缺点
- 依赖底层干预质量,真实方向不准确会影响效果。
- 需多次查询模型导致计算成本和响应时间增加。
未来可研究如何在保证效果的前提下减少查询次数,平衡性能与效率。