RAC: Efficient LLM Factuality Correction with Retrieval Augmentation
英文题目:《RAC: Efficient LLM Factuality Correction with Retrieval Augmentation》
中文题目:《RAC:通过检索增强实现高效的大语言模型事实性校正》
发布于: arxiv
级别:无
摘要
大语言模型(LLMs)在广泛的自然语言处理(NLP)任务中展现出了令人瞩目的成果,但它们常常会产生事实性错误的输出。本文介绍了一种简单而有效的低延迟后校正方法——检索增强校正(RAC),旨在提升大语言模型的事实性表现,且无需额外的微调。我们的方法具有通用性,可与任何经过指令微调的大语言模型配合使用,并且与先前的方法相比,延迟大幅降低。RAC将大语言模型的输出分解为原子事实,并应用检索到的内容进行细粒度的验证和校正过程,以验证和校正大语言模型生成的输出。我们广泛的实验表明,在两个流行的事实性评估数据集上,RAC相较于最先进的基线方法有高达 30%的提升,验证了其在不同大语言模型中,无论是否集成检索增强生成(RAG)时的有效性和稳健性。
本文聚焦的问题
本文聚焦的核心问题是大语言模型生成内容时存在的幻觉问题,即使采用检索增强生成(RAG)技术,模型仍可能输出不符合事实的内容,这在医疗、教育等领域可能造成危害。同时,针对现有利用检索内容进行后校正的方法(如RARR、CRITIC等)存在检索和校正过程繁琐、 latency高、易引入新错误等问题,本文旨在提出一种更高效、通用的解决方案,在不额外微调模型的前提下提升大语言模型输出的事实性。
本文提出的方法
本文提出的方法是检索增强校正(RAC),这是一种轻量且通用的后处理方法,无需额外微调模型,可用于任何指令微调的大语言模型,旨在提升模型输出的事实性。
其核心流程是:先将大语言模型生成的内容分解为独立的原子事实,再利用检索到的内容对这些原子事实进行细粒度的验证和校正,最后据此修正原始输出。
具体来看,对于未使用检索增强生成(RAG)的模型,RAC会直接基于检索到的文档集,纠正提取出的错误陈述并保留正确陈述,再将这些陈述输入修订模块修正原始输出。
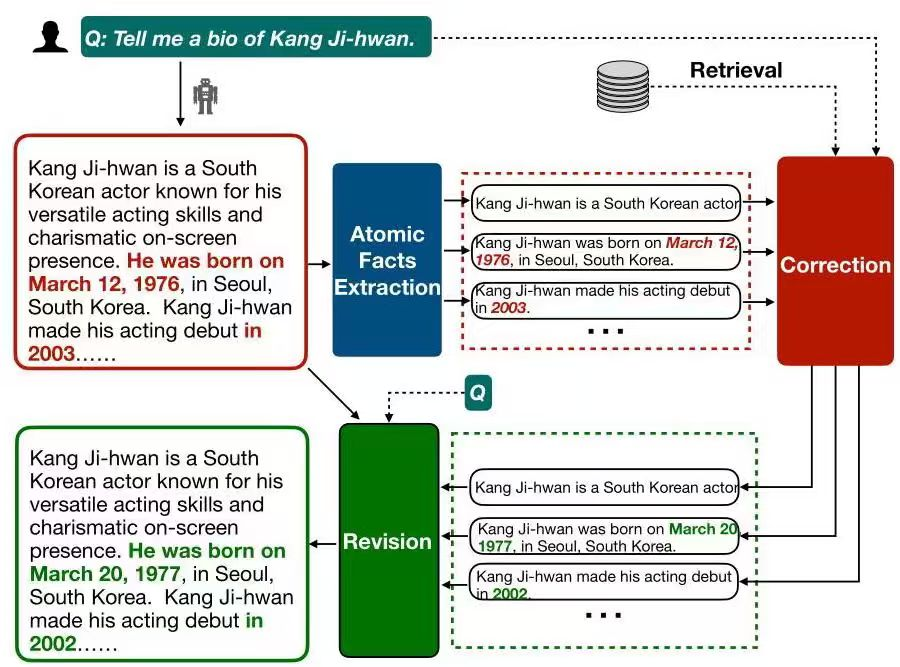
对于使用了RAG的模型,由于其生成内容多数正确,RAC会先增加一个验证环节,仅对经验证为错误的陈述进行校正,以减少因纠正正确内容而引入的新幻觉,之后再进行修订。
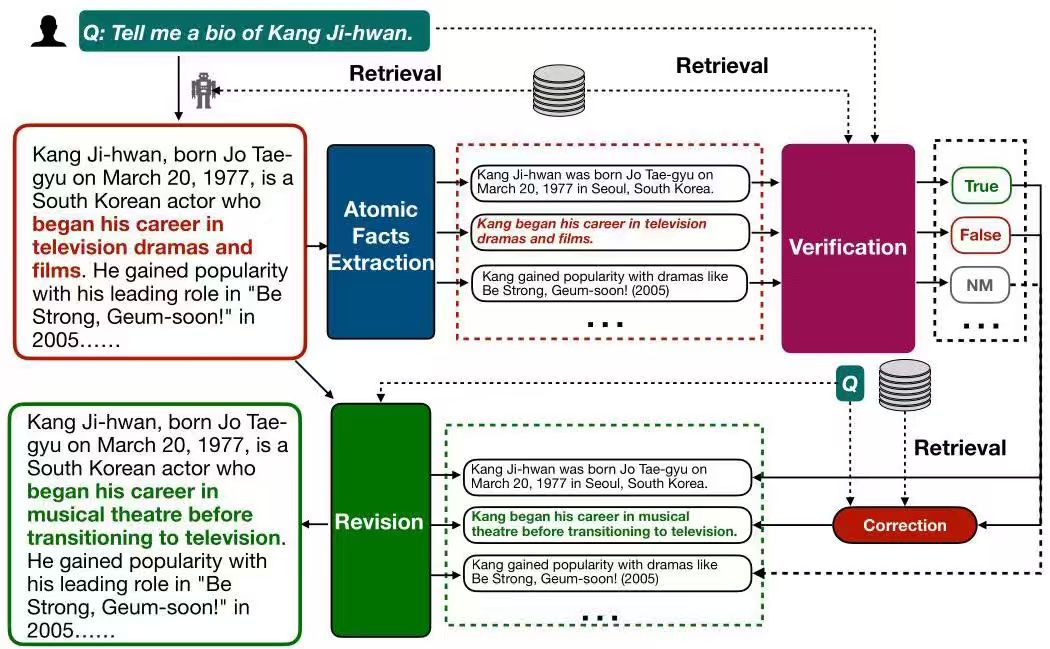
该方法通过一次检索和一次校正,大幅降低了延迟,且在有或没有RAG的情况下都能适用。
阅读总结
优点:
- 只进行一次检索和校正,延迟降低。适用于各类指令微
- 调模型,无需重新训练。
缺点:
- 依赖检索质量,资料错误会影响校正效果。
- 可能引入新幻觉,少数情况校正过程产生新错误。
未来扩展至更多文本类型,适配更大模型并增强可解释性。