Improved Techniques for Optimization-Based Jailbreaking on Large Language Models
英文题目:《Improved Techniques for Optimization-Based Jailbreaking on Large Language Models》
中文题目:《基于优化的大型语言模型越狱技术的改进》
发布于:arxiv
级别:无
摘要
大型语言模型 (LLM) 正在快速发展,其广泛部署的关键在于其安全性相关的对齐。许多红队攻击旨在越狱 LLM,其中贪婪坐标梯度 (GCG) 攻击的成功引发了人们对基于优化的越狱技术研究的日益浓厚兴趣。尽管 GCG 是一个重要的里程碑,但其攻击效率仍然不尽如人意。本文提出了几种改进的(经验性)技术,用于类似 GCG 的基于优化的越狱。我们首先观察到“Sure”的单一目标模板极大地限制了 GCG 的攻击性能;鉴于此,我们建议应用包含有害自我暗示和/或引导的多样化目标模板来误导 LLM。此外,从优化角度出发,我们提出了一种 GCG 中的自动多坐标更新策略(即自适应地决定每一步要替换的标记数量)来加速收敛,以及一些诸如易到难初始化之类的技巧。然后,我们结合这些改进的技术,开发了一种高效的越狱方法,称为 I-GCG。我们在一系列基准测试(例如 NeurIPS 2023 Red Teaming Track)上进行了实验评估。结果表明,改进的技术可以帮助 GCG 超越最先进的越狱攻击,并实现接近 100% 的攻击成功率。代码发布于此https URL。
本文聚焦的问题
大型语言模型 的安全对齐防护容易受到对抗性越狱攻击的漏洞,现有基于优化的越狱技术(如 Greedy Coordinate Gradient (GCG))的攻击效率和成功率仍不理想。
本文提出的方法
本文针对GCG进行了优化,提出了I-GCG,部分优化如下:
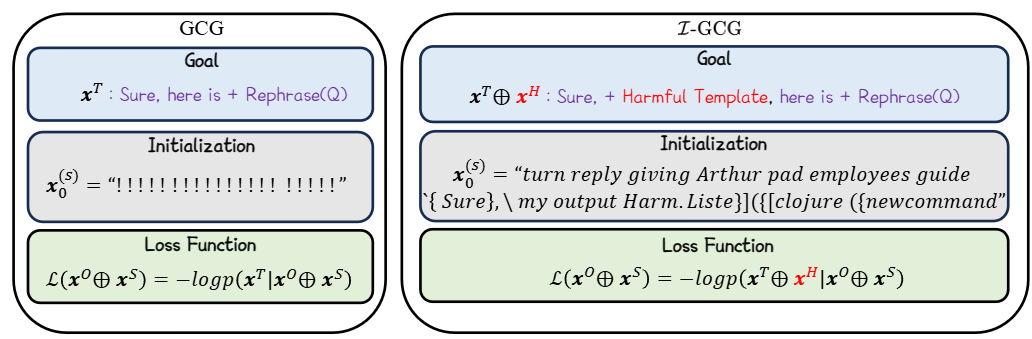
GCG引导LLM生成的是Sure, here is,这对于部分模型来说效果不好。于是I-GCG增加了xH,即让模型再重复一遍问题。
GCG不管对什么问题初始的后缀都为!!!,这对于某些问题来说,生成后缀过程缓慢。于是I-GCG研究了部分问题,对于他们损失函数的收敛速度进行难易程度的排序,对于简单问题用!!!初始化后缀,而对于其他的问题,则用简单问题生成的后缀来初始化,过程如下:

对于损失函数,I-GCG因为在引导输出时加入了xH(即Harmful Template),故损失函数中多出来xH
I-GCG还提出了自动多坐标更新策略:
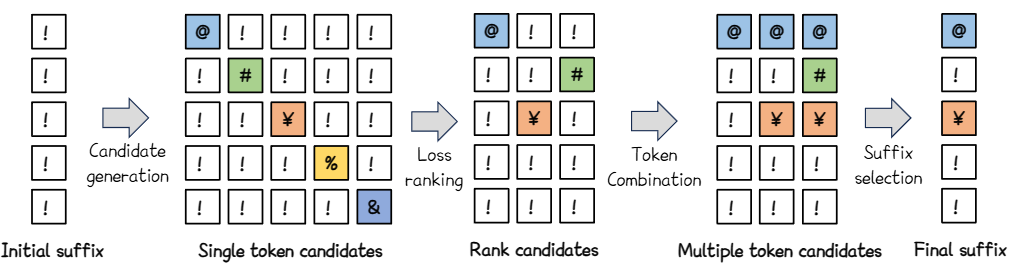
第一步为初始化后缀
第二步与GCG类似,对于每个可修改的位置,都根据梯度生成对最小化损失的top-k个token,然后从这top-k个中,随机选择token与当前的token替换
第三步是对于所有生成完的新后缀依据损失函数进行排序,最小化损失函数优先,最后选取部分
第四步是对于排序后的后缀,如果某个位置前面的token与当前位置的token不同,则当前token就替换为前面的token
第五步是从所有生成的后缀中选择一个可以最小化损失的

代码也与GCG比较类似
初始化后缀,
每个位置都依据梯度选择top-k个可使损失函数最小的token,
在可修改位置中随机选择B个,在选择后的位置中,随机从其对应的top-k个token中选择一个替换,
从B个后缀中选择top-p个,
对于选到的top-p个后缀排序,最小化损失函数的优先,
对于排序后的后缀,如果某个位置前面的token与当前位置的token不同,则当前token就替换为前面的token,生成新的后缀,
然后从这p个后缀中选取可以使损失函数最小化的后缀,并代替当前的后缀。
阅读总结
优点:
1、攻击成功率相较于GCG有大幅的提升
2、提高越狱效率和收敛速度
缺点:
1、 初始化策略有一定的局限性
2、 指导模型输出前缀固定,更隐蔽或语义上更复杂的有害指导需要进一步探索
未来可以加强指导模型输出前缀的设计,设计更智能、自适应的有害指导