TextGrad: Automatic "Differentiation" via Text
英文题目:《TextGrad: Automatic “Differentiation” via Text》
中文题目:《TextGrad:文本自动“微分”》
发布于: arxiv
级别:无
摘要
人工智能正在经历一场范式转变,其突破是由协调多个 large language models (LLMs) 和其他复杂组件的系统实现的。因此,为复合 AI 系统开发有原则的自动化优化方法是最重要的新挑战之一。神经网络在其早期也面临着类似的挑战,直到反向传播和自动微分通过使优化变得轻而易举而改变了该领域。受此启发,我们推出了 TEXTGRAD,这是一个通过文本执行自动“微分”的强大框架。TEXTGRAD 反向传播 LLM 提供的文本反馈,以改进复合 AI 系统的各个组件。在我们的框架中,LLM 提供丰富、通用、自然的语言建议来优化计算图中的变量,范围从代码片段到分子结构。TEXTGRAD 遵循 PyTorch 的语法和抽象,并且灵活易用。它可以直接用于各种任务,用户只需提供目标函数,而无需调整框架的组件或提示。我们展示了 TEXTGRAD 在各种应用中的有效性和通用性,从问题解答和分子优化到放射治疗计划。无需修改框架,TEXTGRAD 将 GPT-4o 在 Google-Proof Question Answering 中的 zero-shot 准确率从 51% 提高到 55%,在优化 LeetCode-Hard 编码问题解决方案方面产生 20% 的相对性能提升,改进了推理提示,设计了具有理想计算机结合的新型类药物小分子,并设计了具有高特异性的放射肿瘤治疗计划。TEXTGRAD 为加速下一代 AI 系统的开发奠定了基础。
本文聚焦的问题
当前AI系统多依赖专家手工设计和启发式调整,缺乏原则性、自动化的优化方法,难以高效地对复合AI系统中的各个组件进行优化以提升整体性能。
文章提出了TEXTGRAD框架,通过 LLMs 生成自然语言形式的 “文本梯度”,并借鉴反向传播思想在复合系统的计算图中传播这些反馈,实现对各组件的自动化优化,以应对复合AI系统优化的挑战。
本文提出的方法
textgrad将AI系统表示为计算图,其中变量是输入和输出:
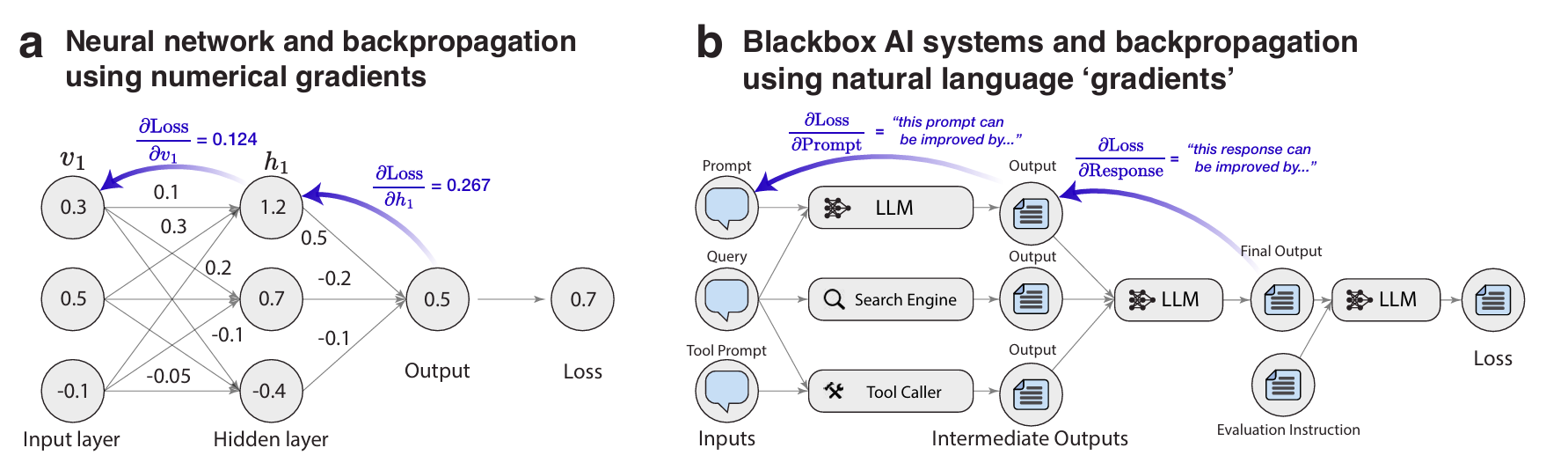
这里的a图就是神经网络,b图就是一个大的AI系统。textgrad借鉴了神经网络中的通过反向传播更新权重的方法,同样也是要计算损失,梯度等,但是这里所有的损失和梯度都是由文字表示的。
对于:
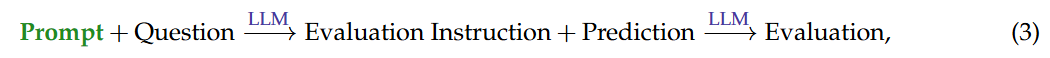
其梯度计算如下:

注意,这里的原来的AI系统是Prompt->Prediction,后面的Evaluation是计算梯度额外增加的。这里先计算了Prediction的梯度,即直接将Evaluation Instruction和Prediction给LLM,然后得出Evaluation,然后再计算Prompt梯度。
这里Prompt梯度文本如下:

得知梯度后,就可以对Prompt进行更新:

示例如下:

下面是TEXTGRAD 框架对问题答案进行迭代优化示例:
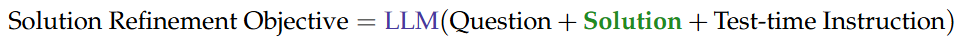

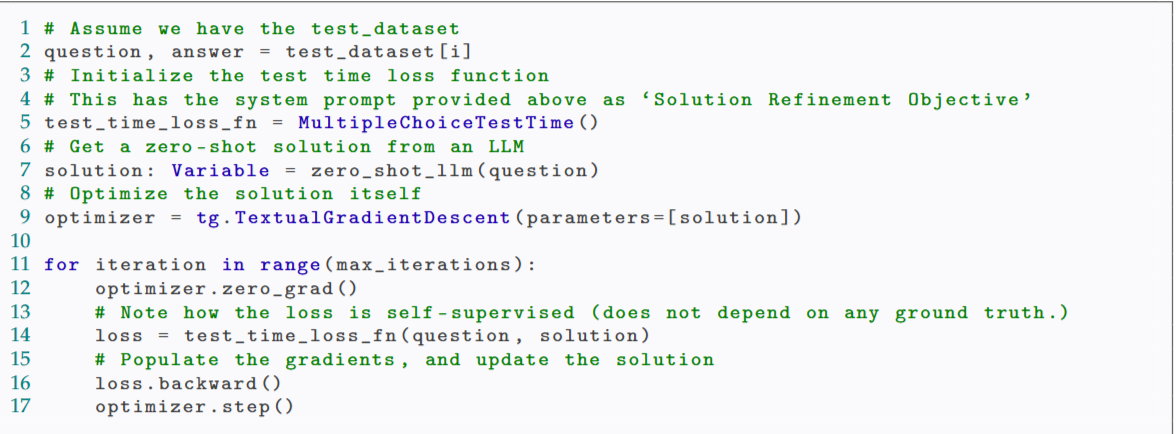
2:question是问题,answer是问题的标准答案
5:初始化了一个损失函数,即Solution Refinement Objective
7:初始化solution,这里的solution即为解决方案
9:初始化优化器,parameters中是要优化的变量
11:执行 max_iterations 次
12:清零之前计算的梯度,确保每次迭代的梯度计算是独立的
14:前向传播,计算损失
16:反向传播,计算梯度
17:参数更新,进行优化
阅读总结
优点:
1、自动化优化能力突出
2、易用性高,兼容性好
缺点:
1、对部分系统的提升有限
未来可以提升优化算法性能