Highlight & Summarize: RAG without the jailbreaks
英文题目:《Highlight & Summarize: RAG without the jailbreaks》
中文题目:《高亮与总结:无需担心越狱问题的检索增强生成》
论文作者:Giovanni Cherubin, Andrew Paverd
发布于: arxiv
发布时间:2025-08-04
级别:无
摘要
防止大型语言模型(LLMs)的越狱和模型劫持是一项重要但具有挑战性的任务。例如,在与聊天机器人交互时,恶意用户可能输入精心设计的提示词,促使大语言模型生成不良内容或执行与其预期用途完全不同的任务。针对此类攻击的现有缓解措施通常依赖于强化大语言模型的系统提示词,或使用经过训练的内容分类器来检测不良内容或离题对话。然而,由于可能的输入和不良输出空间非常庞大,这些概率性方法相对容易被绕过。
在本文中,我们提出并评估了 “高亮与总结”(H&S),这是一种用于检索增强生成(RAG)系统的新设计模式,能够从设计上防止这些攻击。其核心思想是执行与标准 RAG 流程相同的任务(即基于相关来源为问题提供自然语言答案),但从不向生成式大语言模型透露用户的问题。这一目标通过将流程拆分为两个组件来实现:一个是高亮器,它接收用户的问题并从检索到的文档中提取相关段落(“高亮内容”);另一个是总结器,它接收这些高亮段落并将其总结为连贯的答案。我们描述了 H&S 的几种可能实现方式,并从正确性、相关性和响应质量方面评估了其生成的回答。令人惊讶的是,当使用基于大语言模型的高亮器时,大多数 H&S 的响应被判定为优于标准 RAG 流程的响应。
本文聚焦的问题
本文聚焦于解决检索增强生成(RAG)系统中存在的越狱攻击、模型劫持以及现有防御措施局限性的问题。
- 越狱攻击:指恶意用户通过输入精心设计的提示词,促使大型语言模型(LLM)生成不良内容(如损害公司声誉的内容),或生成误导性陈述(甚至可能构成具有法律约束力的不当承诺,例如诱使聊天机器人提供产品折扣)。这种攻击会直接影响系统的安全性和可信度,甚至带来法律风险。
- 模型劫持:指恶意用户将生成式 LLM 用于预期用途之外的任务,例如利用公司客服聊天机器人总结大量无关文本,消耗系统资源。这违背了 RAG 系统的设计初衷,造成资源浪费。
- 现有防御措施局限性:现有缓解攻击的方法(如强化 LLM 的系统提示词、使用内容分类器检测不良内容或离题对话)多为概率性方法。由于可能的输入和不良输出空间极为庞大,这些方法相对容易被绕过,无法从根本上解决问题。
本文提出的方法
整个系统的大致流程图如下:
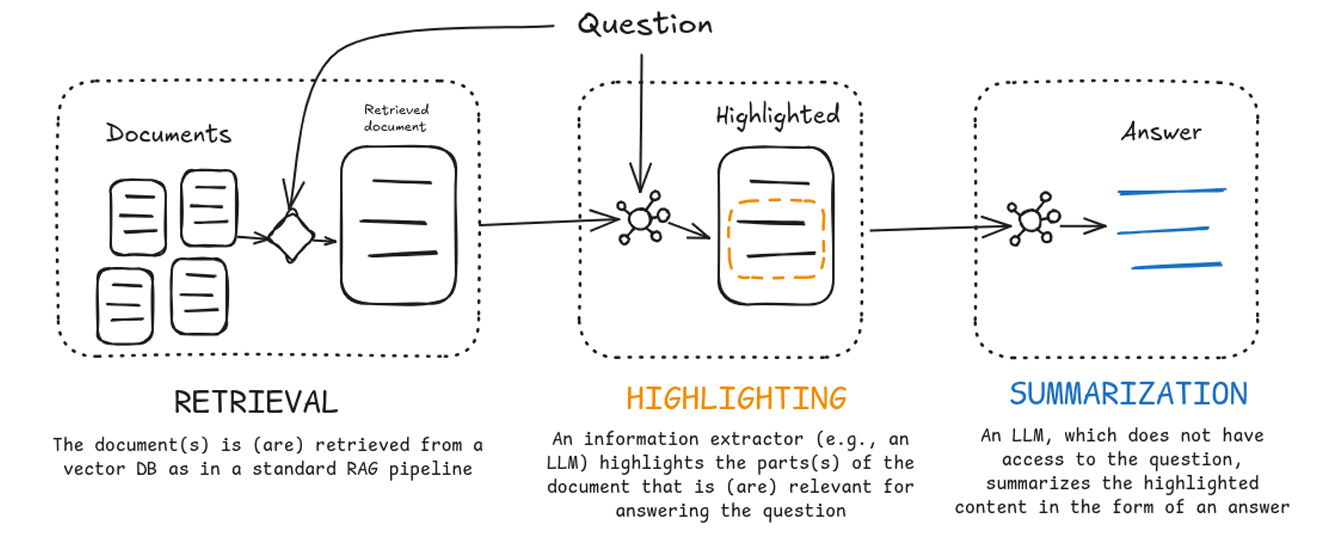
RETRIEVAL:使用RAG技术,从文件中检索出与用户问题相关的部分
HIGHLIGHTING:将检索出的文本和用户的问题给LLM,让LLM来判断问题和文本是否相关,并且提取出文本中相关度高的内容
这里对该部分可以进行优化,文章中提出两个优化:
1、在提取文本前对用户内容进行回答,即同时根据问题,回答以及与用户问题相关的文本。这可以辅助LLM更好地理解上下文,并从原始文档中识别出相关文本。
2、引入RapidFuzz,其主要功能是进行模糊字符串匹配。这里让LLM提取出文本中相关度高的内容作为初步提取的文本,然后用RapidFuzz对该文本与问题进行匹配,文章设置的阈值为 95,对文本再提纯一次。确保内容是忠实于原始源文档。
其返回格式为{“answer”: str, “text_extracts”: list[str]}。
SUMMARIZATION:将上一步提取的文本进行整个,并回答这个问题。
这里SUMMARIZATION主要是有两个任务,1)猜测提取的文本旨在回答什么问题(返回给用户),2)以答案的形式重新描述提取的文本(用于评估)。
其返回格式为{“guessed_question”: str, “answer”: str}
这里需要注意该系统的HIGHLIGHTING生成的是连续的高亮(相关度高)段,这可以有效的防止恶意拼接,例如:

如果攻击者可能希望系统输出“You won a $10 voucher”(你赢得了10美元代金券),他们就会尝试让上面内容高亮,但是由于HIGHLIGHTING生成的是连续的高亮段,所以可以避免。
但是通过操控HIGHLIGHTING,使其在从检索到的文档中提取相关段落时,故意遗漏某些关键信息仍然是可行的,例如:

用户可能试图让HIGHLIGHTING只提取部分条件(对于例子,即只生成一部分内容),导致最终由SUMMARIZATION生成的答案虽然正确,但却不完整。
阅读总结
优点:
1、安全性高且性能更优
2、对 LLM 训练数据的依赖低
缺点:
1、处理效率较低,耗时长
2、拒绝回答能力不足
未来可以探索减少幻觉的潜力以及优化拒绝回答能力