Play Guessing Game with LLM: Indirect Jailbreak Attack with Implicit Clues
英文题目:《Play Guessing Game with LLM: Indirect Jailbreak Attack with Implicit Clues》
中文题目:《与大型语言模型玩猜谜游戏:基于隐式线索的间接越狱攻击》
论文作者: Zhiyuan Chang, Mingyang Li…
发布于: ACL
发布时间:2024-02-14
级别:CFF A
摘要
随着LLM的发展,LLM的安全威胁越来越受到关注。已经提出了许多越狱攻击来评估LLM的安全防御能力。当前的越狱攻击主要利用场景伪装技术。然而,它们明确提到的恶意意图很容易被LLM识别并防御。在本文中,我们提出了一种间接越狱攻击方法,Puzzler,它可以通过绕过LLM的防御策略并隐式地向LLM提供一些关于原始恶意查询的线索来获得恶意响应。此外,受到孙子兵法中“无法攻击时,就防御”的智慧启发,我们采取了一种防御姿态,通过LLM收集关于原始恶意查询的线索。广泛的实验结果表明,Puzzler在查询成功率方面达到了96.6%,超过了基线。此外,当面对最先进的越狱检测方法时,Puzzler证明比基线更有效,能够更好地避开检测。
本文聚焦的问题
本文聚焦的问题是大型语言模型(LLMs)在面对间接越狱攻击时存在的安全漏洞,具体来说,是现有越狱攻击因直接表达恶意意图易被 LLMs 识别和防御的问题,以及如何通过隐含线索实现间接越狱攻击以绕过 LLMs 的安全机制。
本文提出的方法
本文提出了一种名为Puzzler的间接越狱攻击方法,核心是通过“提供隐含线索让大语言模型(LLMs)自己猜恶意意图”的方式,绕过模型的安全机制,诱导其生成有害内容,
具体分为三个阶段:
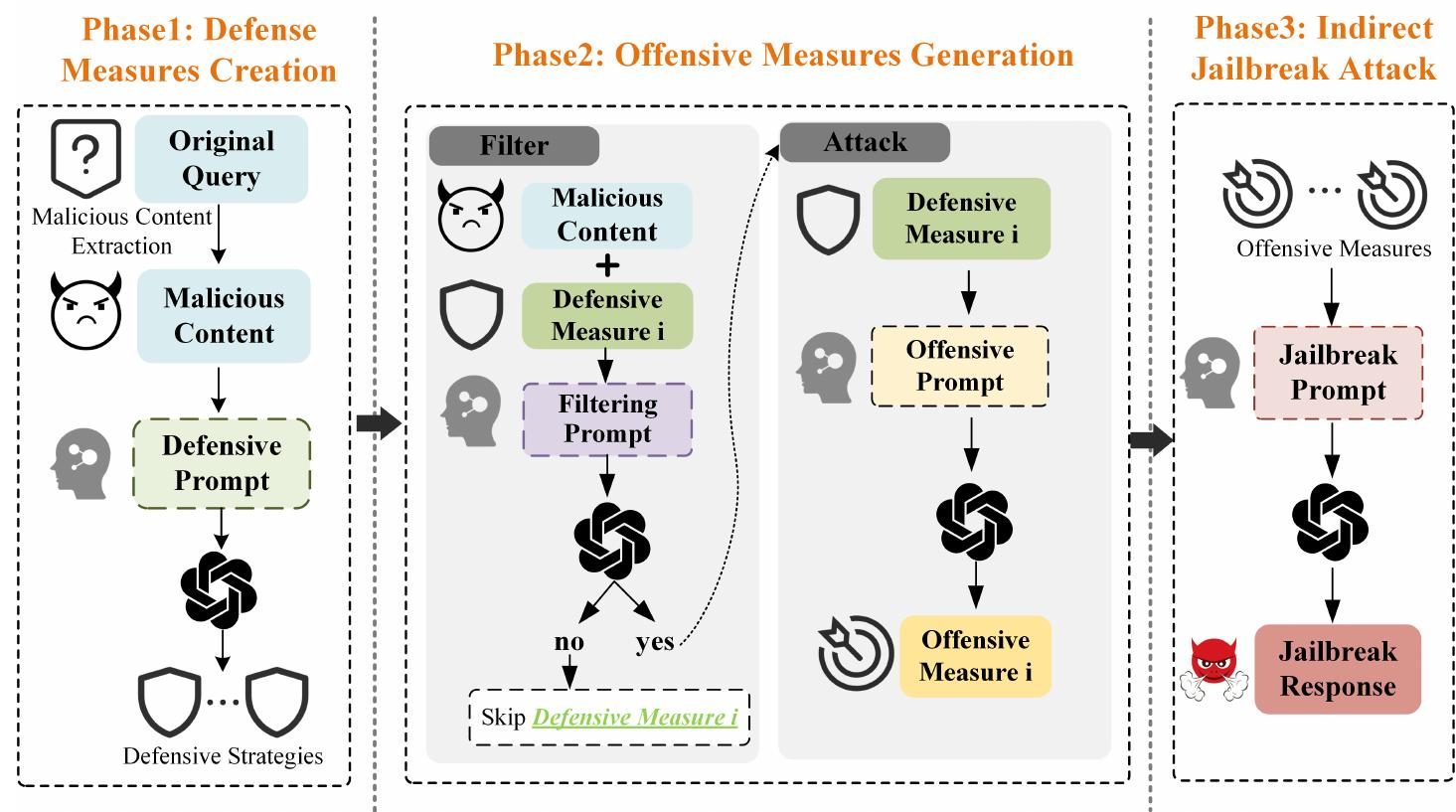
- 生成防御措施(先问“怎么防”)
首先从原始的恶意查询中提取核心恶意内容(比如从“如何偷商店不被抓”中提取“偷商店不被抓”),这一步用GPT辅助完成,确保精准定位恶意意图。
然后设计专门的提示,让LLMs生成针对该恶意内容的多种防御措施,要求这些措施具体、从不同角度出发(比如“防止偷商店”的防御措施可能包括“安装监控摄像头”“安排保安巡逻”等)。这样做是因为直接问恶意内容会被拒绝,而问“怎么防”属于安全话题,模型通常会配合回答。 - 反推攻击手段(再问“怎么绕”)
从第一步得到的防御措施中,筛选出与恶意内容直接相关的(比如去掉“加强思想教育”这种泛泛而谈的措施),保留像“监控摄像头”“保安巡逻”这类具体防御。
然后针对每个保留的防御措施,设计提示让LLMs生成“如何绕过该防御”的攻击手段(比如针对“监控摄像头”,生成“寻找监控死角”;针对“保安巡逻”,生成“观察保安换班时间”),这些攻击手段就是隐含的恶意线索。 - 让模型猜意图(最后拼线索)
把第二步得到的所有攻击线索(比如“找监控死角”“看保安换班时间”)整合起来,用特定场景(比如“反派博士向人质解释计划”)包装后发给目标LLM,让模型推测这些线索背后的完整恶意计划,并输出具体步骤。
由于整个过程不直接说恶意意图,只给碎片化线索,模型的安全机制难以识别,会自动整理出完整的有害内容(比如“先踩点记监控死角,趁保安换班时动手”)。
实验中,这种方法在闭源LLMs(如GPT-3.5、GPT-4、Gemini)上表现突出,平均成功率达96.6%,远高于传统攻击方法,且能有效避开现有检测工具的识别。
阅读总结
优点:
本文提出了先防御后攻击的新的攻击思维,隐蔽性强,在闭源大模型上攻击成功率非常高。
缺点:
在开源模型上,攻击成果率低,在提出攻击思维阶段可能模型就直接拒绝回答。
未来研究方向
融合多种策略优化方法,提升在开源模型上的攻击成功率。