BagofTricks: Benchmarking of Jailbreak Attacks on LLMs
英文题目:《BagofTricks: Benchmarking of Jailbreak Attacks on LLMs》
中文题目:《技巧集合:大语言模型越狱攻击的基准测试》
论文作者: Zhao XU,Fan LIU,Hao LIU
发布于: NeurIPS
发布时间:2024-11-06
级别:CFF A
摘要
尽管大型语言模型(LLM)已经显示出在零样本方式下执行复杂任务的能力,但它们容易受到越狱攻击,并且可以被操纵以产生有害输出。最近,越来越多的工作将越狱攻击分为令牌级和提示级攻击。然而,以前的工作主要忽视了越狱攻击的多样关键因素,大部分研究集中在LLM漏洞上,缺乏对防御增强LLM的探索。为了解决这些问题,我们评估了各种攻击设置对LLM性能的影响,并为越狱攻击提供了一个基线基准,鼓励采用标准化的评估框架。具体来说,我们从目标和攻击两个层面评估了LLM上实施越狱攻击的八个关键因素。我们进一步在两个广泛使用的数据集上对六种防御方法进行了七种典型的越狱攻击,涵盖了大约320个实验和大约50,000个GPU小时在A800-80G上。我们的实验结果突显了需要标准化基准以评估这些攻击对防御增强LLM的必要性。我们的代码可以在 https://github.com/usail-hkust/Bag_of_Tricks_for_LLM_Jailbreaking 上获得
本文聚焦的问题
本文聚焦于大型语言模型(LLMs)的越狱攻击问题,旨在深入研究攻击机制、影响因素及防御策略,虽然已有研究对 LLMs 越狱攻击进行了分类,但存在明显缺陷。一方面,未充分考虑影响越狱攻击的多种关键因素,包括目标模型层面(如模型模板、大小)和攻击者层面(如能力、预算)的因素;另一方面,对防御增强型 LLMs 的研究欠缺,缺乏对防御方法如何影响攻击效果的广泛基准测试 。
本文提出的方法
本文针对大型语言模型(LLMs)越狱攻击研究存在的不足,提出了JailTrickBench这一方法,用于评估越狱攻击的有效性。
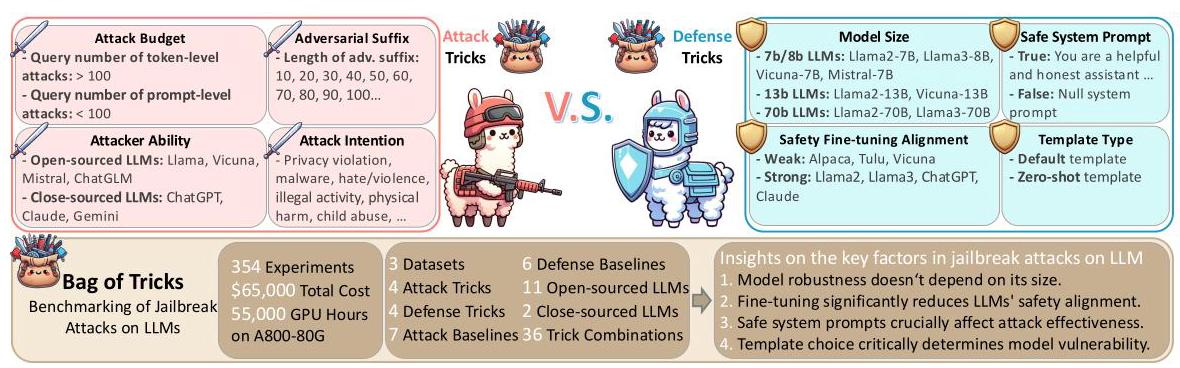
- 建立基准测试框架JailTrickBench
从目标模型和攻击者两个维度,确定了8个对越狱攻击有显著影响的因素。在目标模型方面,包含模型大小、是否经过安全微调、是否有安全系统提示(如设置 “你是有帮助且诚实的助手……” 的提示语或无提示 )、使用的模板类型(默认模板和零样本模板 );在攻击者方面,包含攻击者能力(使用开源模型如Llama、Vicuna,或闭源模型如ChatGPT、Claude )、攻击预算(词元级攻击查询次数超100,提示级攻击查询次数少于100 )、对抗性后缀长度(从10到100等不同长度 )、攻击意图(如隐私侵犯、恶意软件、暴力等不同攻击目的 )。 - 采用多种攻击与防御技术进行实验
攻击技术:选取7种常见且具有代表性的越狱攻击技术,像基于优化的攻击(例如HotFlip )、基于迭代的攻击(如AutoJailbreak )等,同时考虑4种攻击基线和36种攻击招数组合,从不同角度对模型发起攻击测试。
实验结果:
(1)模型的鲁棒性不取决于其规模;
(2)微调会显著影响语言模型的鲁棒性,通常会降低它们的安全对齐性;
(3)安全提示在越狱攻击的有效性中起着关键作用;
(4)模板的选择对于确定模型对对抗性攻击的脆弱性至关重要;
(5)攻击者的技能水平显著影响攻击性能,更先进的语言模型能取得更好的结果;
(6)更长的对抗性后缀在一定程度上增加了生成越狱响应的可能性,超过这一点后效果趋于平稳;
(7)对于令牌级越狱,攻击成功率(ASR)随着攻击预算的增加而显著提高,而对于提示级越狱,攻击预算的影响很小;
(8)在评估语言模型的鲁棒性和安全性时,考虑攻击背后的具体意图很重要。
阅读总结
优点:
本文提出的方法从攻击方和防御方两个维度,多个攻击方法等进行实验,因素考量全面。
缺点:
成本高昂,对于闭源模型研究不够深入。
未来研究方向:
对于新型攻击手段和优化的防御策略进行测试评估,在推动大模型安全发展。