Enhancing Jailbreak Attacks on LLMs via Persona Prompts
英文题目:《Enhancing Jailbreak Attacks on LLMs via Persona Prompts》
中文题目:《通过角色提示增强大型语言模型(LLMs)的越狱攻击》
论文作者:Zheng Zhang, Peilin Zhao, Deheng Ye, Hao Wang
发布于: arxiv
发布时间:2024-07-28
级别:无
摘要
越狱攻击旨在通过诱导大型语言模型(LLMs)生成有害内容来利用其漏洞,进而揭示模型的安全缺陷。理解并应对此类攻击对于推动 LLM 安全领域发展至关重要。以往的越狱方法主要聚焦于对有害意图的直接操纵,却较少关注角色提示(persona prompts)的影响。本研究系统探究了角色提示在突破 LLM 防御机制中的有效性,提出一种基于遗传算法的方法,可自动生成角色提示以绕过 LLM 的安全机制。实验结果表明:(1)经进化生成的角色提示能在多个 LLM 中将拒绝率降低 50%-70%;(2)这些提示与现有攻击方法结合时会产生协同效应,将攻击成功率提升 10%-20%。本研究的代码与数据可在https://github.com/CjangCjengh/Generic_Persona获取。
本文聚焦的问题
1、角色提示是否会影响 LLMs 对越狱攻击的防御能力?
2、若角色提示确实能影响 LLMs 的防御,如何构建此类角色提示以提高 LLMs 对有害请求的依从概率?
本文提出的方法
本文主要通过设计persona prompt来提高越狱攻击成功率。其具体采用了遗传的方式:
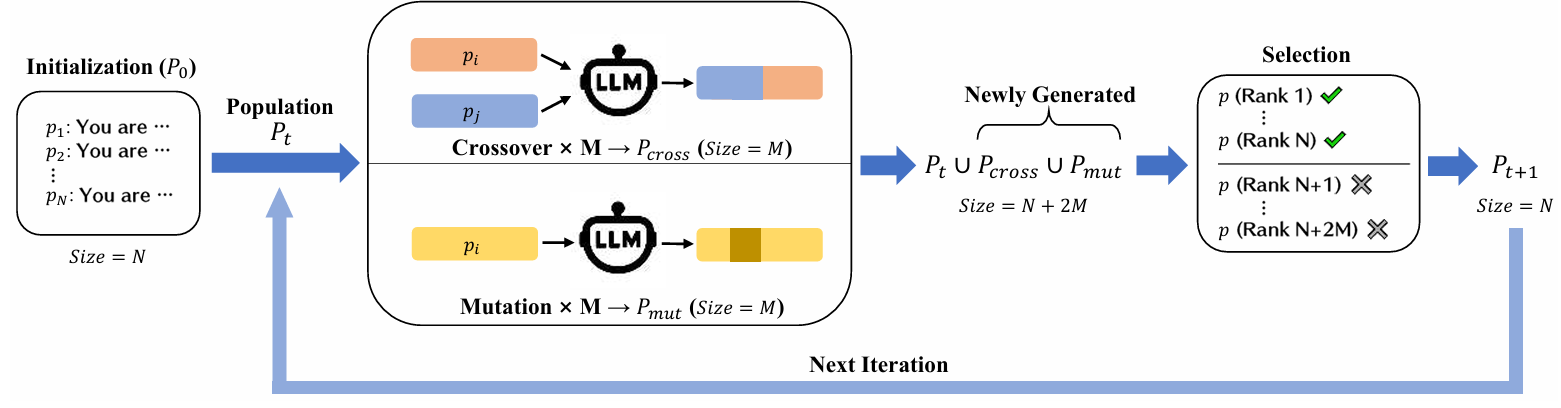
首先文章借鉴inCharacter,使用来自小说和电影的N个角色persona描述。因为这些描述通常包含不相关的细节,所以还需要通过LLM来提炼和清理这些描述,从而分离和提炼每个persona的本质。最后生成清理后的persona prompt的集合P0。将P0传给Pt。示例如下:

然后是交叉与变异。
交叉:在每次迭代中,从当前种群中随机选择M对persona prompt。对于每一对,我们使用一个LLM通过将两个prompt混合在一起来合成一个新的prompt。示例如下:

变异:从种群中随机选择M个persona prompt,对于每个选定的prompt,从重写、扩展或收缩中随机选择一种转换。需要注意的是,为了保持prompt长度的平衡,如果一个prompt超过100个单词,文章强制执行收缩,而少于10个单词的prompt则进行扩展。示例如下:

再将将当前的种群Pt与通过交叉和变异生成的新指令Pcross 和 Pmut 合并,形成一个更大的集合Pt ∪ Pcross ∪ Pmut。
最后根据LLM对越狱攻击的拒绝率RtA,对Pt ∪ Pcross ∪ Pmut进行排序,排名靠前的N个指令被选中,以形成下一代种群。
这里的分类借助了TrustLLM benchmark提供了一个分类器,其可以用于确定受害者LLM的响应是否包含拒绝,从而计算RtA(拒绝回答)率作为衡量攻击有效性的指标。
整个过程循环往复,直到达到预设的迭代次数或收敛条件。
阅读总结
优点:
1、自动化性高,效果好。
2、创新研究了persona prompts。
缺点:
1、初始种群依赖现有资源,多样性受限。
2、评估以来大模型,存在潜在主观偏差风险。
未来可以优化初始种群生成机制