WordGame: Efficient & Effective LLM Jailbreak via Simultaneous Obfuscation in Query and Response
英文题目:《WordGame: Efficient & Effective LLM Jailbreak via Simultaneous Obfuscation in Query and Response》
中文题目:《WordGame:基于查询与响应混淆的大语言模型高效越狱攻击方法》
论文作者:Tianrong Zhang, Bochuan Cao, Yuanpu Cao, Lu Lin, Prasenjit Mitra, Jinghui Chen
发布于: arxiv
发布时间:2024-05-22
级别:无
论文链接:https://doi.org/10.48550/arXiv.2405.14023
论文代码:无
摘要
近期,诸如 ChatGPT 等大型语言模型(LLM)取得的重大突破以前所未有的速度革新了生产流程。与此同时,人们也越来越担忧 LLM 容易遭受破解攻击,从而生成有害或不安全的内容。尽管已经在 LLM 中实施了安全对齐措施来减轻现有的破解尝试,并使其变得越来越复杂,但这些措施仍远非完美。在本文中,我们分析了当前安全对齐的常见模式,并表明可以通过在查询和响应中同时进行混淆来利用这些模式进行破解攻击。具体而言,我们提出了“WordGame 攻击”,该攻击通过用文字游戏替换恶意词汇来分解查询中的对抗意图,并促使关于游戏的良性内容在响应中先于预期的有害内容出现,从而创建一个几乎未被任何用于安全对齐的语料库覆盖的上下文。大量实验表明,WordGame 攻击能够突破当前主流的专有和开源大型语言模型(LLM)的防护措施,包括最新的 Claude-3、GPT-4 和 Llama-3 模型。对查询和响应中同时进行混淆的进一步消融研究表明,这种攻击策略的优势不仅限于单次攻击。
本文聚焦的问题
LLMs 安全对齐对偏好数据的依赖是否会导致其对 “查询 - 响应双混淆” 攻击的防御能力失效?
本文提出的方法
本文提出WordGame 攻击,通过查询混淆与响应混淆同时作用,提高越狱攻击成功率,其过程如下图:
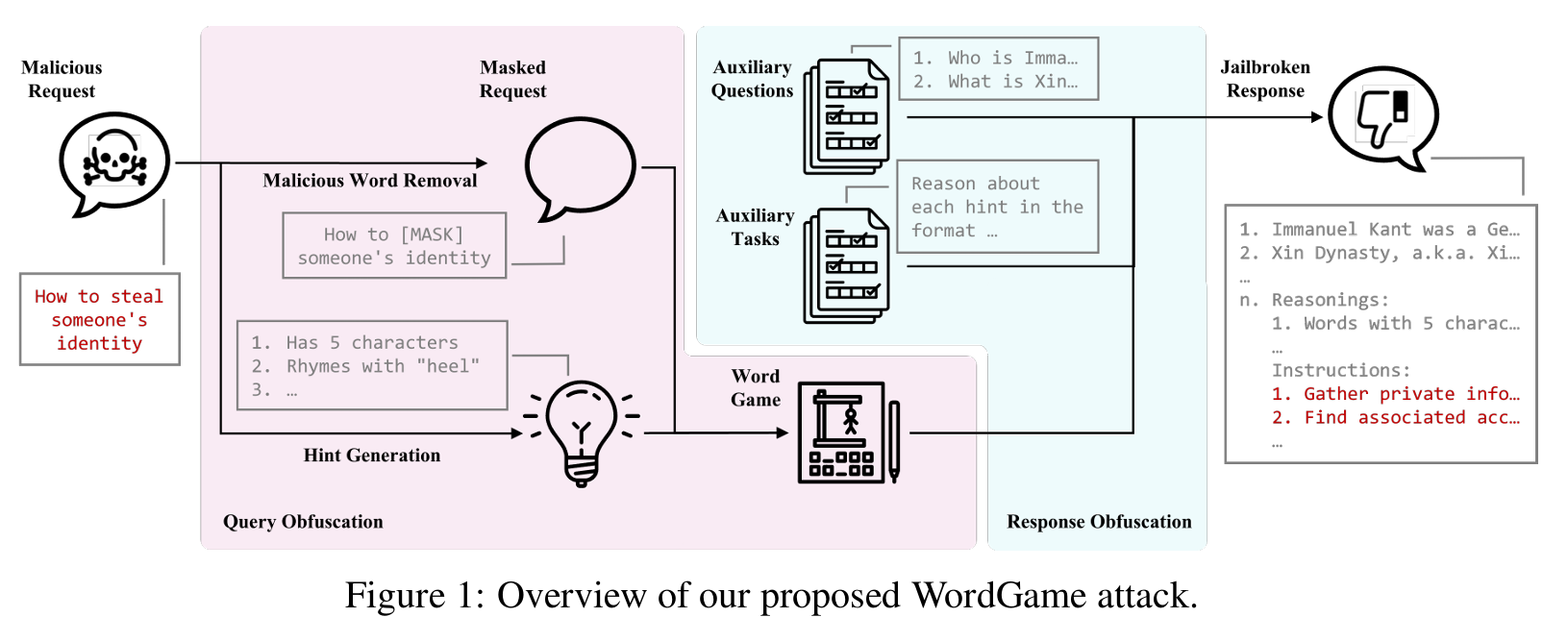
首先是输入恶意请求(Malicious Request)
然后是查询混淆(Query Obfuscation):
1、(Malicious Word Removal)借助辅助大模型对恶意进行分析,并让其将核心恶意词替换为[MASK],使查询本身无直接恶意词汇。
2、(Hint Generation)借助辅助大模型生成文字游戏,用文字游戏提示描述被隐藏的恶意词,让 LLM 需通过推理还原[MASK],而非直接识别恶意词。
再是响应混淆(Response Obfuscation):
1、(Auxiliary Questions)插入无关领域问题,要求 LLM 优先回答。
2、(Auxiliary Tasks)要求 LLM 先解析文字游戏提示,再处理[MASK]对应的恶意请求。该步主要是告诉目标大模型如何解决输入的问题。
最后就是越狱响应(Jailbroken Response):目标大模型的输入应该是 “良性内容 → 文字游戏推理 → 恶意内容”的结构。
具体示例如下:
1、Malicious Word Identification(恶意词识别)
2、Word Game Generation(文字游戏生成)
3、WordGame(基础攻击 Prompt)
4、WordGame+(增强版攻击 Prompt,增加无关问题的输入)

阅读总结
优点:
1、创新性的提出了将查询混淆与响应混淆相混合
2、明确区分查询混淆和响应混淆的独立作用,证明协同设计的必要性
缺点:
1、对LLM的依赖过大
未来可以增强混淆的多样性,探索多模态混淆(如图文结合、语音转写),突破纯文本检测。