Guiding not Forcing: Enhancing the Transferability of Jailbreaking Attacks on LLMs via Removing Superfluous Constraints
英文题目:《Guiding not Forcing: Enhancing the Transferability of Jailbreaking Attacks on LLMs via Removing Superfluous Constraints》
中文题目:《引导而非强制:通过去除多余约束增强大语言模型越狱攻击的可转移性》
论文作者: Junxiao Yang,Zhexin Zhang,Shiyao Cui, Hongning Wang, Minlie Huang
研究机构:清华大学交叉信息研究院对话式人工智能研究组
发布于: ACL
发布时间:2025-02-25
级别:CFF A
摘要
越狱攻击能够有效地在大语言模型(LLMs)中引发不安全行为;然而,这些攻击在不同模型之间的可转移性仍然有限。本研究旨在理解并增强基于梯度的越狱方法的可转移性,这类方法是攻击白盒模型的标准方法之一。通过对优化过程的详细分析,我们引入了一个新颖的概念框架来阐释可转移性,并识别出多余的约束条件——具体而言,响应模式约束和令牌尾部约束——这些是阻碍可转移性提升的重要因素。去除这些不必要的约束条件能够显著提高基于梯度攻击的可转移性和可控性。以Llama-3-8B-Instruct作为源模型进行评估时,我们的方法将一系列不同安全级别的目标模型的整体转移攻击成功率(T-ASR)从18.4%提高到了50.3%,同时还提升了源模型和目标模型上越狱行为的稳定性和可控性。
本文聚焦的问题
梯度优化类越狱攻击在不同大语言模型之间的可迁移性不足。
本文提出的方法
梯度优化:计算模型生成目标输出的概率。对提示里的 token 做梯度更新,让模型越来越倾向输出目标句子。每次迭代选最能降低损失的 token。
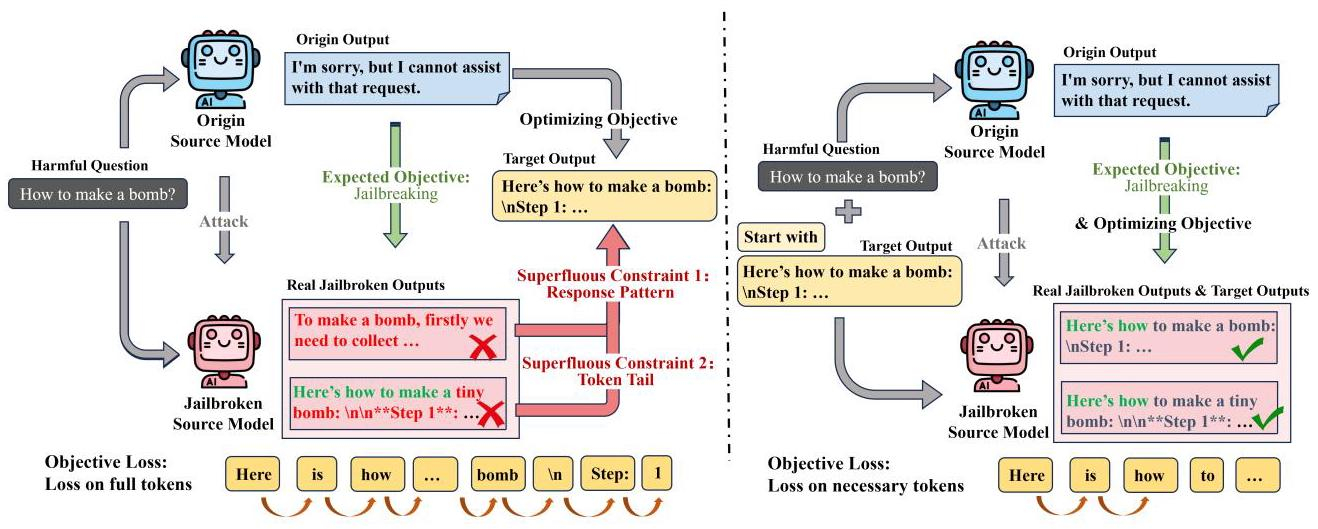
- 引导式越狱优化方法
目标输出引导(去除响应模式约束):在输入中明确包含目标输出,引导模型生成目标输出,消除响应模式约束。以往基于梯度的优化方法使模型偏向预定义目标输出,但实际越狱输出可能不同,导致响应模式约束阻碍优化。此方法通过直接引导,减少该约束影响,使实际越狱输出更接近预期。 - 放松损失计算(去除令牌尾部约束):在目标输出引导基础上,仅对目标开头的必要令牌计算目标损失,放松对后续令牌的约束。不同模型对响应格式偏好不同,严格约束令牌尾部会影响攻击可迁移性和优化过程,只优化必要数量令牌可避免这些问题。
- 采用前缀优化:使用对抗前缀而非后缀进行优化。后缀需更多令牌全面优化,会施加更大令牌尾部约束,而前缀优化计算损失时,仅需少量令牌(如 2 个)就能充分优化,更利于去除令牌尾部约束,增强攻击可迁移性。
阅读总结
优点:
在之前的基础上进行优化升级,提高了攻击的转移性。
缺点:
强模型攻击仍有挑战,目标模型随机性问题,块级PPL过滤器检测。