Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
英文题目:《Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning》
中文题目:《Search-R1:利用强化学习训练大型语言模型以进行推理并利用搜索引擎》
论文作者:Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, Jiawei Han
发布于: COLM 2025
发布时间:2024-08-05
级别:无
摘要
在大型语言模型(LLM)中,高效获取外部知识和最新信息对于有效的推理和文本生成至关重要。给具备推理能力的先进 LLM 提供提示,使其在推理过程中使用搜索引擎的做法往往并非最佳选择,因为 LLM 可能无法完全掌握如何以最佳方式与搜索引擎进行交互。本文介绍了 Search-R1,这是一种强化学习(RL)的扩展,用于推理框架,其中 LLM 学习在逐步推理过程中自主生成(多个)搜索查询,并进行实时检索。Search-R1 通过多轮搜索交互来优化 LLM 的推理轨迹,利用检索到的标记掩码进行稳定的 RL 训练,并采用简单的基于结果的奖励函数。在七个问答数据集上的实验表明,Search-R1 在相同设置下比各种基于检索的基准方法提高了 41%(Qwen2.5-7B)和 20%(Qwen2.5-3B)的性能。本文还提供了关于 RL 优化方法、LLM 选择和响应长度动态在检索增强推理中的实证见解。代码和模型检查点可在该网址获取:https://github.com/PeterGriffinJin/Search-R1
本文聚焦的问题
将 RL 应用于搜索和推理场景提出了三个关键挑战:
1、RL 框架和稳定性——如何有效地将搜索引擎集成到 LLM 的 RL 方法中,同时确保稳定的优化,尤其是在结合检索到的上下文时,仍然不清楚。
2、多轮交错推理和搜索——理想情况下,LLM 应该能够进行迭代推理和搜索引擎调用,并根据问题的复杂性动态调整检索策略。
3、奖励设计——为搜索和推理任务设计有效的奖励函数仍然是一个根本性的挑战,因为尚不清楚简单的基于结果的奖励是否足以指导 LLM 学习有意义且一致的搜索行为。
本文提出的方法
文章介绍了SEARCH-R1,这是一个新颖的RL框架,使LLM能够以交错的方式与搜索引擎进行交互,并进行自己的推理。
文章使用两种方式(PPO和GRPO)对训练模型进行优化,具体过程图如下:
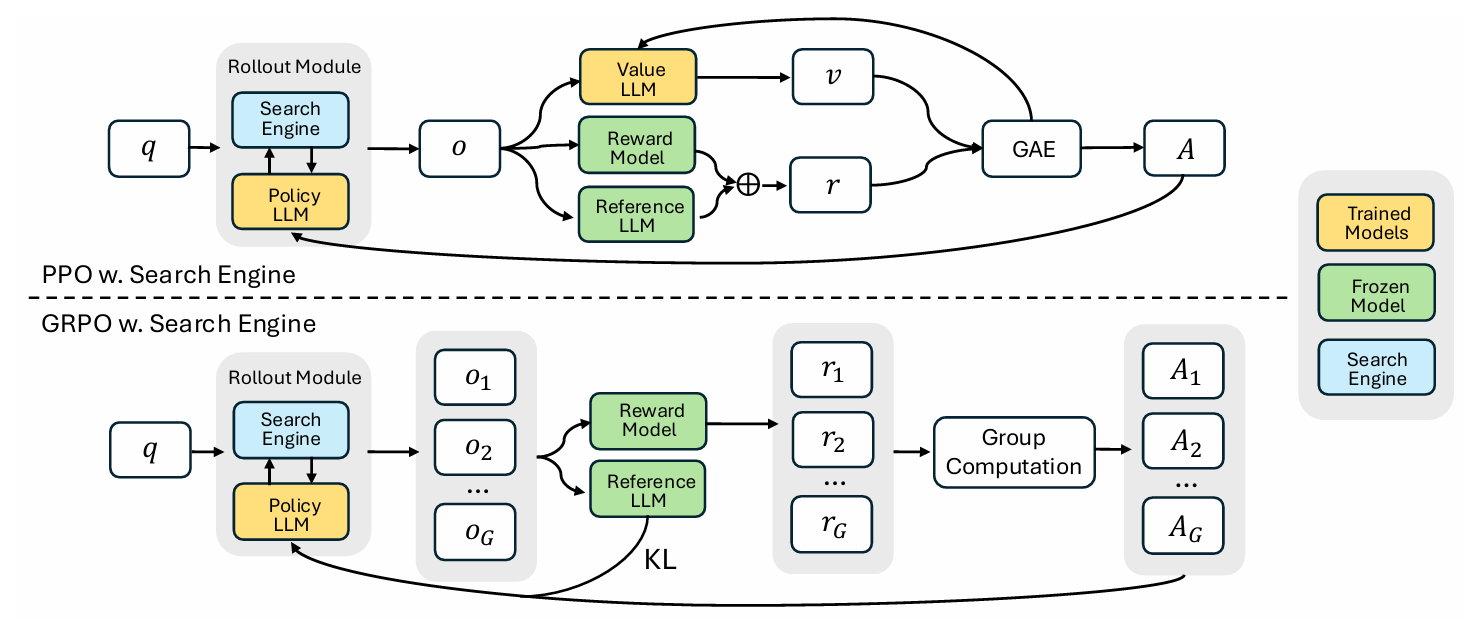
首先对于PPO:
q→Rollout Module:
输入问题q到Rollout Module,启动 “推理 + 搜索” 的轨迹生成过程,关于Rollout Module内部具体过程下面讲解。Rollout Module→o:
Rollout Module结合Policy LLM的推理和Search Engine的结果,生成完整轨迹o(包含推理步骤、搜索调用、中间信息等)。o→Value LLM→v:
轨迹o输入Value LLM,Value LLM输出对轨迹o的价值估计v。o→Reward Model:
轨迹o输入Reward Model,计算该轨迹的基础奖励(如答案的精确匹配度)。o→Reference LLM:
轨迹o输入Reference LLM(参考模型,冻结不更新),生成参考输出,用于计算Policy LLM与参考模型的 KL 散度(防止策略更新幅度过大)。Reward Model+Reference LLM→r:
Reward Model的基础奖励与Reference LLM相关的KL 正则项结合,得到最终奖励信号r。v+r→GAE→A:
价值估计v(当前状态价值)和奖励r(即时奖励)输入GAE(广义优势估计)模块,计算优势函数A(衡量 “实际奖励与预期价值的差距”)。GAE→Value LLM:
GAE计算的 “优势 / 误差信号” 反馈给Value LLM,用于更新价值模型。A→Policy LLM:
利用优势值A更新Policy LLM的参数。
然后是GRPO:
- 前面第一,二步同 PPO。
Rollout Module→o₁, o₂, ..., o_G:
Rollout Module生成 **G条轨迹 **(组大小为G),每条轨迹o_i是独立的 “推理 + 搜索” 结果。o_i→Reward Model:
每条轨迹o_i输入Reward Model,计算对应奖励r_i(如单条轨迹的答案精确匹配度)。o_i→Reference LLM:
每条轨迹o_i输入Reference LLM,计算Policy LLM与Reference LLM的KL 散度(正则项,防止策略偏离)。Reward Model→r₁, r₂, ..., r_G:
Reward Model为每条轨迹o_i输出单独奖励r_i。r₁, r₂, ..., r_G→Group Computation→A₁, A₂, ..., A_G:
所有组内轨迹的奖励输入Group Computation模块,Group Computation为每条轨迹o_i计算优势值A_i。Reference LLM+A₁, A₂, ..., A_G→Policy LLM:
A₁, A₂, ..., A_G与Reference LLM相关的KL 正则项结合,更新Policy LLM的参数。
下面是Rollout Module内部的具体过程:
这是用于指导Policy LLM的提示词:

这内部的伪代码:

输入:输入查询 x、策略模型 πθ、搜索引擎 R 和最大行动预算 B
输出:最终的生成响应 y
初始化一个空的y。y 将累积 LLM 生成的所有文本和检索到的所有信息,形成完整的交互轨迹。
初始化行动计数器。b 用于追踪当前是第几轮交互,防止模型无限循环。
循环:
在每一轮主循环开始时,初始化一个空的yb。yb 将存储当前轮次中 LLM 生成的token,例如一段思考、一个搜索查询或最终答案。
LLM 在这个内部循环中持续生成token,直到生成一个特定的结束token。
y ← y + yb: 将当前完成的行动序列 yb 添加到总的交互序列 y 中。
如果 yb 中检测到搜索请求,调用搜索引擎 R,传入查询 q,获取检索结果 d。
如果 yb 中检测到最终答案,算法终止。
如果 LLM 生成的既不是有效的搜索请求,也不是最终答案,算法会在 y 中添加一条“我的行动不正确,让我重新思考”的信息,促使 LLM 在下一轮中重新评估。
行动计数器 b 增加,进入下一轮交互。
阅读总结
优点:
1、SEARCH-R1通过强化学习让 LLM 自主决定何时搜索、搜索什么、如何整合结果,实现多轮 “推理 - 搜索 - 推理” 闭环,尤其适合需要多跳推理的复杂任务。
2、支持不同 RL 算法(PPO/GRPO)和 LLM 类型(Base/Instruct 模型),且在在域和域外数据集上均有效,泛化能力突出。
缺点:
1、仅依赖 “答案精确匹配” 作为奖励,在需要细粒度推理或复杂任务中可能无法充分引导 LLM 学习。
未来可以设计分层奖励(如 “推理合理性”“检索相关性”“答案准确性”),引导 LLM 在过程中学习。