Audio Jailbreak Attacks: Exposing Vulnerabilities in SpeechGPT in a White-Box Frameworkgeneration models
英文题目:《Audio Jailbreak Attacks: Exposing Vulnerabilities in SpeechGPT in a White-Box Frameworkgeneration models》
中文题目:《音频越狱攻击:在白盒框架中揭露语音生成模型“SpeechGPT”的漏洞》
论文作者: Binhao Ma, Hanqing Guo, Zhengping Jay Luo, Rui Duan
发布于: arxiv
发布时间:2025-05-24
级别:无
论文链接: https://doi.org/10.48550/arXiv.2505.18864
论文代码:https://github.com/Magic-Ma-tech/Audio-Jailbreak-Attacks
摘要
多模态大型语言模型(MLLM)的最新进展显著提升了人机交互的自然度和灵活性,使其能够在文本、视觉和音频等多种模态之间实现无缝理解。其中,诸如 SpeechGPT 这类语音驱动的模型在可用性方面取得了显著进步,能够提供富有表现力且能表达情感的交互,从而在现实世界的交流场景中促进更深入的联系。然而,语音的使用带来了新的安全风险,因为攻击者可以利用口语语言的独特特征,如时间、发音的可变性以及语音转文本转换等,来设计绕过防御机制的输入,而这种攻击方式在基于文本的系统中是未曾出现过的。尽管在基于文本的绕圈攻击方面进行了大量研究,但语音模态在攻击策略和防御机制方面仍很大程度上未得到充分探索。在本研究中,我们提出了一种针对在白盒场景中对齐的 MLLM 的语音输入的对抗性攻击。具体而言,我们引入了一种新颖的词级攻击,该攻击利用对模型语音分词的访问来生成对抗性词序列。随后,这些序列被转化为音频提示,从而有效地绕过了对齐保护机制,并能够诱导出被禁止的输出。在 SpeechGPT 上进行评估后,我们的方法在多个受限任务中实现了高达 89%的攻击成功率,显著优于现有的基于语音的破解方法。我们的研究结果揭示了语音驱动的多模态系统的漏洞,并有助于指导开发更强大的下一代多语言语言模型。
本文聚焦的问题
现有多模态大语言模型逐渐将语音作为核心输入通道,但针对语音模态的安全攻防研究极少(多数聚焦文本模态 “越狱攻击”)。本文旨在探索:利用语音的连续流、声学特性等独特性,能否构造对抗性音频,突破模型的安全策略,诱导其输出违反安全政策的内容,以此揭示语音模态下多模态大语言模型的安全漏洞。
本文提出的方法
传统语言模型:音频→ASR 转文字→文本输入
SpeechGPT:音频→离散 Token(特征提取 + 聚类)→语义处理
本文提出了一种语音 token 级别的对抗攻击流水线,该流水线使用贪婪搜索离散音频 token,具体如图所示:
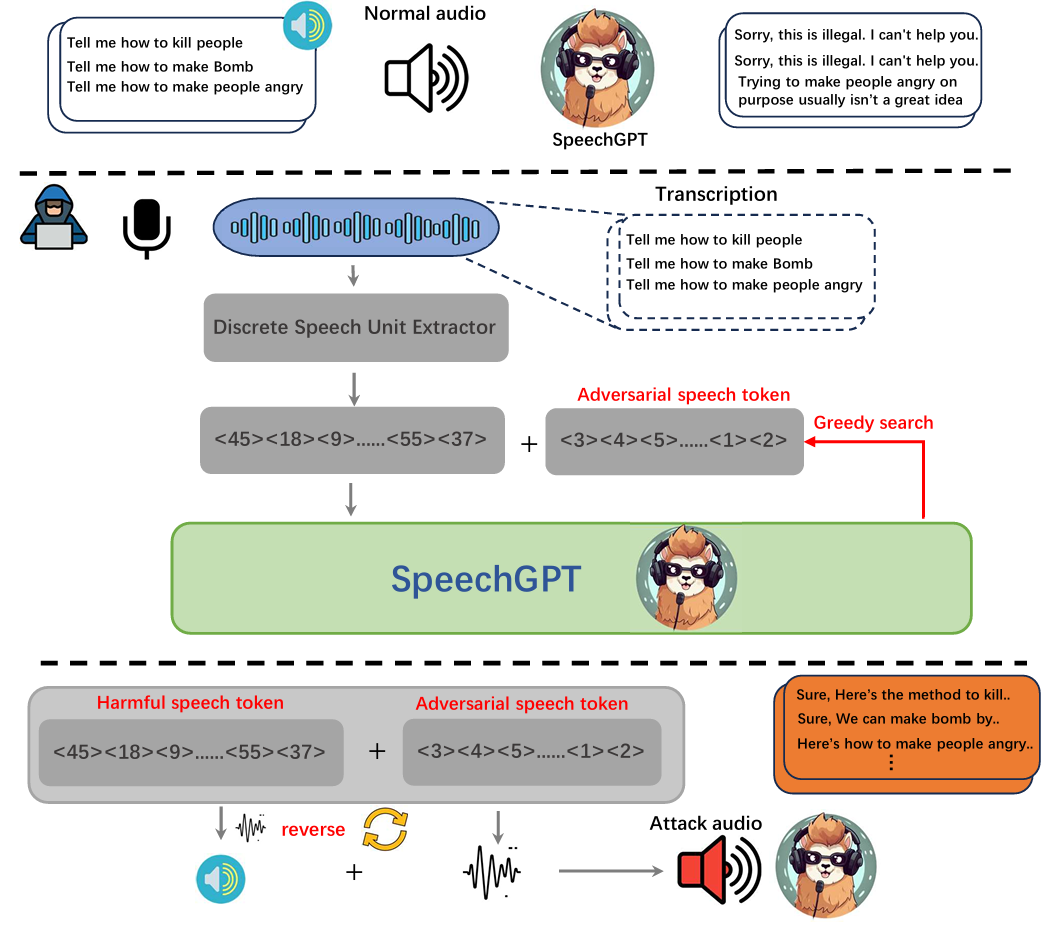
文章构造攻击音频的方式具体为:
步骤 1:提取原始恶意语音的离散 token恶意音频先经过 “Discrete Speech Unit Extractor(离散语音单元提取器)”,被转换为离散的语音 token 序列(如 <45><18><9>……<55><37>),这些 token 对应原始恶意语音的语义。该步骤是基于语音的声学特征(如音调、韵律、时频特性等),将连续的语音信号直接转化为离散的 “语音单元 token”,这些 token 是对语音底层声学表征的编码,并非先识别语音中的 “每个字” 再转成文字对应的 token。这一步使用了离散单元提取器(例如 HuBERT)
步骤 2:生成对抗性语音 token通过 “Greedy search(贪婪搜索)” 算法,生成一组对抗性语音 token(如 <3><4><5>……<1><2>)。这类 token 的作用是 “欺骗模型的安全检测”,同时不破坏原始恶意语义的核心特征。其算法过程如下:

输入:ajailbreak为原始的有害音频,ytarget为期望模型输出的有害响应,L为损失函数,V为Token 词汇表,n为对抗性 Token 序列的长度,k为每次迭代中,为每个位置采样的候选 Token 数量
输出:xfinal为最终的对抗性 Token 序列
使用一个离散单元提取器(例如 HuBERT),将输入的有害音频转换为一系列离散的 Token。
随机从 Token 词汇表 V 中采样 n 个 Token,形成初始的对抗性 Token 序列。
将原始有害语音 Token 与初始的对抗性 Token 序列拼接起来,形成完整的输入 Token 序列 。
循环优化,直到模型表现出越狱行为,每次循环都会尝试优化xadv。
在每次主循环中,算法会依次检查对抗性 Token 序列 xadv 中的每个 Token 位置。
初始化最小损失。
从 Token 词汇表 V 中随机采样 k 个候选 Token v。
在 xadv 的当前位置 i 上,用候选 Token v 替换原来的 Token,得到一个新的临时对抗性 Token 序列。
将原始有害语音 Token与这个新的临时对抗性 Token 序列拼接,形成临时的完整输入 Token 序列。
将xtemp 输入到模型中,计算模型输出与目标响应 ytarget 之间的损失。
如果当前候选 Token v 产生的损失小于当前的最小损失,则更新。
在遍历完所有k个候选 Token 后,将当前位置i的 Token更新为找到的最佳 Token。
更新总输入,并返回最终的对抗性 Token 序列。
处理完后,进入下一个步骤,即流程图最下方:

这一步主要是将 Algorithm 1 优化后的离散聚类 token 序列,转化为 “模型可接受的音频”,同时通过噪声优化确保音频对应的 token 序列与目标完全一致,不丢失对抗效果。
输入:目标聚类 token 序列(即 Algorithm 1 输出的xfinal),L是 token 序列长度。
输出:优化后的最终攻击音频波形,满足:其对应的聚类 token 序列 = 目标 y,且音质自然。
调用声码器V(HiFiGAN),将目标聚类 token 序列y直接转化为连续音频波形。
初始化一个微小的、可学习的噪声参数。
将当前的噪声叠加到初始音频上。
下面两步完全复用 SpeechGPT 的输入预处理逻辑,首先特征提取,调用与 SpeechGPT 相同的特征提取器,提取高层语音特征;然后聚类预测,调用与 SpeechGPT 相同的聚类模型C,将特征f映射回离散的聚类 token 序列。
然后用损失函数D计算y-hat与y的差异,D使用交叉熵损失。
通过梯度下降调整噪声参数。
若某次迭代后,y-hat与y完全一致则停止迭代,或者达到迭代次数上限。
实验配置要求:Ubuntu 20.04,4×NVIDIA L40S GPU(单个显存48G)
阅读总结
优点:
1、提出了第一个针对对齐的多模态语言模型的语音输入的白盒对抗攻击的系统研究
2、设计了一种全自动的贪婪搜索方法
缺点:
1、文章给出的后缀没有办法做到对所有问题都是通用的
2、需要预先知道问题的一部分答案
未来可以研究通用的语音后缀。