ReLOAD: Using Reinforcement Learning to Optimize Asymmetric Distortion for Additive Steganography
英文题目:《ReLOAD: Using Reinforcement Learning to Optimize Asymmetric Distortion for Additive Steganography》
中文题目:《Reload:利用强化学习优化非对称失真进行加性隐写》
论文作者:Xianbo Mo; Shunquan Tan; Weixuan Tang; Bin Li; Jiwu Huang
发布于:TIFS
发布时间:2023-02-10
级别:CCF-A
论文链接: 10.1109/TIFS.2023.3244094
论文代码:无
摘要
最近,非加性隐写的成功表明,与对称代价函数相比,非对称失真可以显著提高安全性能。然而,目前已有的加性隐写方法大多仍基于对称失真。在本文中,我们首次对加性隐写的非对称失真进行了优化,并提出了一个基于A3C (异步优势演员-评论家)的隐写框架,称为ReLOAD。ReLOAD由一个执行器和一个评论者组成,前者指导像素级失真调制的动作选择,后者评估调制失真的性能。 同时,提出了一种考虑嵌入效应的奖励函数来统一隐写和强化学习的目标,从而可以通过学习安全策略来实现嵌入效应的最小化,以最大化总奖励。统计分析表明,与非加性隐写相比,ReLOAD实现了更低的变化率,使嵌入痕迹与载体图像纹理更加一致。在手工设计的基于特征和基于深度学习的隐写分析器上进行的全面实验表明,ReLOAD显著提升了当前加性方法的安全性能,甚至在修改分布更稀疏的情况下优于非加性隐写。
本文聚焦的问题
研究定位
隐写术(Steganography) 是在媒介中隐匿信息的一种信息安全技术。
对手技术:隐写分析(Steganalysis) 旨在检测隐藏痕迹。两者不断博弈推动技术演进。
现代隐写研究可分为两大方向:
- 编码方案(Coding schemes):如 STC、SPC,使得信息嵌入接近速率–失真极限。
- 失真函数(Cost functions):通过衡量修改代价来最小化嵌入痕迹。
现代隐写框架:失真最小化
现代隐写几乎都遵循一个核心思想:在嵌入固定载荷(payload)的前提下,使图像失真(distortion)最小化。
也就是:
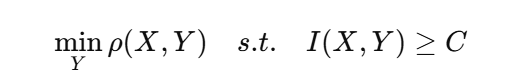
其中:
- :封面图;
- :嵌入后图;
- :嵌入所造成的总失真;
- :载荷(信息量)。
换句话说:我们希望“在尽量不破坏图像统计特征的情况下藏入尽可能多的信息”。
加性隐写
加性隐写是最经典、最广泛使用的隐写框架。
它假设每个像素的修改代价彼此独立,整体失真是所有像素代价的加和:

或更具体地写成:
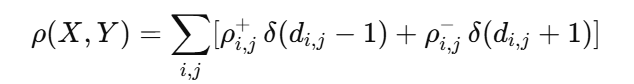
其中:
- :像素修改方向;
- :把像素 +1 的代价;
- :把像素 −1 的代价;
- :指示函数。
加性隐写认为,每个像素的修改对图像失真贡献独立且可加。
这种假设的好处:
- 计算简单;
- 嵌入过程易于用代价函数控制;
对称失真
在加性隐写的多数传统方法中,假设:
即:像素加亮(+1)或变暗(−1)的代价被认为是相同的
问题与局限性
虽然假设简化了计算,但它忽略了图像在不同方向上对扰动的非对称敏感性:
- 在亮度较高的区域,再加亮(+1)可能更明显;
- 在阴影或暗区中,减少亮度(−1)反而不明显;
- 人眼与统计特征对两种改动的响应不同。
因此,没有任何理论理由认为这两个方向的嵌入代价必须相同。 但几乎所有加性隐写算法都默认了这一假设。
非对称失真
为了突破这种限制,研究者提出了非对称失真:
主要方法路线:
| 路线 | 核心思想 | 缺陷 |
|---|---|---|
| (A) 启发式定义原则(CMD、BBM) | 通过人为规则调整 +1/−1 的代价,例如让修改方向在空间上同步(CMD)或块边界保持一致(BBM)。 | 需要迭代嵌入和邻域约束,计算代价高、修改率高。 |
| (B) 对抗梯度方法(ADV-EMB, MCTSteg, GEAP 等) | 通过检测器(CNN)反向传播梯度来指导代价调整。 | 依赖检测器准确性。低载荷时检测器不稳定,梯度噪声大,性能下降。 |
ReLOAD 的核心动机
我们希望在加性框架中,通过强化学习自动学习非对称失真分配策略,在不依赖检测器梯度的情况下最小化嵌入对纹理的影响。该思路将“最小化嵌入影响”转化为强化学习的“最大化累计奖励”问题,通过策略网络实现非对称代价调节。
作者的关键创新
| 传统方法 | ReLOAD 的改进 |
|---|---|
| 对称失真假设:+1 和 −1 修改等价 | 改为非对称失真优化,允许两方向代价不同 |
| 手工规则或梯度导向 | 改为**强化学习(A3C)**自动学习调节策略 |
| 以检测器输出为奖励 | 改为纹理距离差作为奖励(与检测器无关,更稳定) |
| 顺序像素调节(效率低) | 采用并行代理(A3C 多线程),提升训练效率 |
本文提出的方法
总体思路
- 将“非对称失真优化”建模为一个 马尔可夫决策过程 (MDP)。利用 A3C(Asynchronous Advantage Actor-Critic)框架 并行学习每个像素的调节策略。
- 核心目标:将“最小化嵌入影响”转化为强化学习的“最大化累计奖励”,两者之间等价
强化学习框架定义
| 元素 | 定义 | 说明 |
|---|---|---|
| Agent | 每个像素一个代理。仅激活前 (ϵ%) 的高概率像素(称为 有效代理率 EAR)。 | 减少计算量,提高训练效率。 |
| Action | 每个像素动作 ():分别调整 +1/−1 方向代价。若 =1 ⇒ 减小 ();若 ⇒ 减小 ()。 | 通过系数 α=1.25 控制调节强度。 |
| State | 由 (当前载密图 、修改图 、上一动作图 ) 组成。初始动作图为 0。 | 提供上下文信息。 |
| Reward | 基于封面–载密图的纹理距离差定义:计算 SRM 高通滤波器(30个)提取纹理特征 T,再计算。 | 若纹理距离减小 → 奖励为正。 |
| Reward扩散规则 | 为了避免奖励过于稀疏,用固定核 ϕ 将奖励扩散到邻域:中心权½,邻域权1/16,让局部区域共享“好/坏”反馈,从而传播正面经验,促进收敛。 | 让局部正负反馈在邻域传播,提升稳定性。 |
| Actor–Critic 网络 | 共享编码器(8层卷积)+ 双解码分支(各7层反卷积)。输出:策略图 π (3通道,对应动作概率) 与价值图 V。 | 结构称为 DBN (Dual-Branch Network)。 |
训练与优化流程
| 步骤 | 名称 | 主要操作 | 输出结果 |
|---|---|---|---|
| ① | 初始化(Initialization) | 载入封面图 ,初始化失真为对称形式,生成初始状态 。 | 初始状态 |
| ② | 策略执行(Action Sampling) | Actor 网络根据当前状态 输出动作图 。 | 像素级动作分布 |
| ③ | 环境更新(Environment Transition) | 根据动作调整失真矩阵:若 ,则 ;若 (\gamma_{i,j}=-1),则 ;(\alpha = 1.25)。 | 新的非对称失真 |
| ④ | 嵌入与奖励计算(Reward Computation) | 将新的失真送入最优嵌入模拟器生成载密图 (),再用 30 个 SRM 滤波器计算纹理距离差:若纹理距离减小,则奖励 ();反之 ()。 | 奖励图 () |
| ⑤ | 策略更新(Policy Optimization) | 使用 A3C(Advantage Actor-Critic)算法更新网络参数:根据奖励 () 和预测价值 (),计算优势 ()。 | 更新参数 (\theta) |
| ⑥ | 状态转移(State Transition) | 新状态 (),作为下一轮输入。 | 进入下一步循环 |
验证与模型选择
在验证阶段,作者引入两个指标来衡量模型表现:
| 指标 | 含义 | 优化方向 |
|---|---|---|
| DI (Distance of Image textures) | 封面与载密图纹理距离的 L1 归一化值 | 越小越好 |
| RI (Reward Image-wise) | 图像级奖励的平均值 | 越高越好 |
模型选择原则:在验证集上 DI 最小的模型被认为是当前最优策略。
测试与停止条件
在测试阶段,模型不断调整失真直至达到最优点:
- 当下一状态的 DI 开始 上升(变差) 时,认为前一状态最优;
- 停止迭代,输出当前非对称失真矩阵 。
这样可以防止过度优化造成“反向破坏”(即隐写痕迹变明显)
阅读总结
“模型在不断试错中调整每个像素的修改方向, 如果修改让图像纹理更接近原图,它就得到奖励; 经过成千上万次交互后,策略网络学会了最隐蔽的修改方式。”
不足:
-
奖励设计过于手工化:依赖固定 SRM 滤波器计算纹理距离,缺乏可学习或自适应的奖励机制
-
停止条件与超参固定:测试阶段以单步 DI 上升为终止条件,容易过早停止;EAR、α 等关键超参为固定值,缺乏自适应调整。
改进:
- 稳健早停与策略评估:测试时将“DI 上升即停”改为滑动窗口耐心策略(例如 patience=3,仅当 DI 连续多步劣化才停止),或训练一个终止策略头,直接学习“何时停”。
- 将检测器预测不确定性并入奖励,形成“纹理一致性 + 探测难度”的多目标加权。