Generalized Diffusion Detector Mining Robust Features from Diffusion Models for Domain-Generalized Detection
英文题目:《Generalized Diffusion Detector Mining Robust Features from Diffusion Models for Domain-Generalized Detection》
中文题目:《广义扩散检测器:从扩散模型中挖掘出鲁棒的特征,用于领域广义检测》
论文作者:Boyong He; Yuxiang Ji; Qianwen Ye; Zhuoyue Tan; Liaoni Wu
发布于:CVPR
发布时间:2025-06
级别:CCF-A
论文链接: 10.1109/CVPR52734.2025.00927
论文代码:[heboyong/Generalized-Diffusion-Detector: CVPR2025] Generalized Diffusion Detector: Mining Robust Features from Diffusion Models for Domain-Generalized Detection
摘要
领域泛化 (DG) 目标检测旨在提升检测器在未见过场景下的性能。由于实际应用中的复杂变化,这项任务仍然具有挑战性。近年来,扩散模型在多样化场景生成中展现出卓越的性能,这启发我们探索其在改进 DG 任务中的潜力。我们的方法并非生成图像,而是在扩散过程中提取多步中间特征,以获得用于广义检测的领域不变特征。此外,我们提出了一个高效的知识迁移框架,使检测器能够通过特征和对象级对齐继承扩散模型的泛化能力,而无需增加推理时间。我们在六个具有挑战性的 DG 基准测试上进行了广泛的实验。结果表明,与现有的 DG 方法相比,我们的方法在不同领域和损坏类型上实现了 14.0% 的显著提升。值得注意的是,我们的方法甚至在无需访问任何目标领域数据的情况下,就超越了大多数领域自适应方法。此外,与基线相比,扩散引导的检测器平均 mAP 持续提升了 15.9%。我们的工作旨在提出一种有效的领域广义检测方法,并为现实世界场景中的鲁棒视觉识别提供潜在的见解。代码可在“广义扩散检测器”中找到。
本文聚焦的问题
现有的深度伪造(Deepfake)检测方法存在以下三大核心问题:
- 检测与解释割裂
以往方法往往只能提供“真假分类结果”或“文本解释”,无法同时生成两者,导致模型缺乏可解释性与用户信任度。 - 缺乏专门针对伪造检测的多模态机制
一些基于 CLIP 的检测器虽然具备强大的视觉-语言特征提取能力,但缺乏专门设计的文本提示(text prompts)和伪造特征学习机制,难以充分利用 CLIP 的多模态学习潜力。 - CLIP 与大语言模型(LLM)的结合仍未被探索
尽管 CLIP 与 LLM 在文档解析、医学诊断等领域已有成功整合,但在深度伪造检测领域尚无有效的跨模态融合方案,难以实现既准确又可解释的检测。
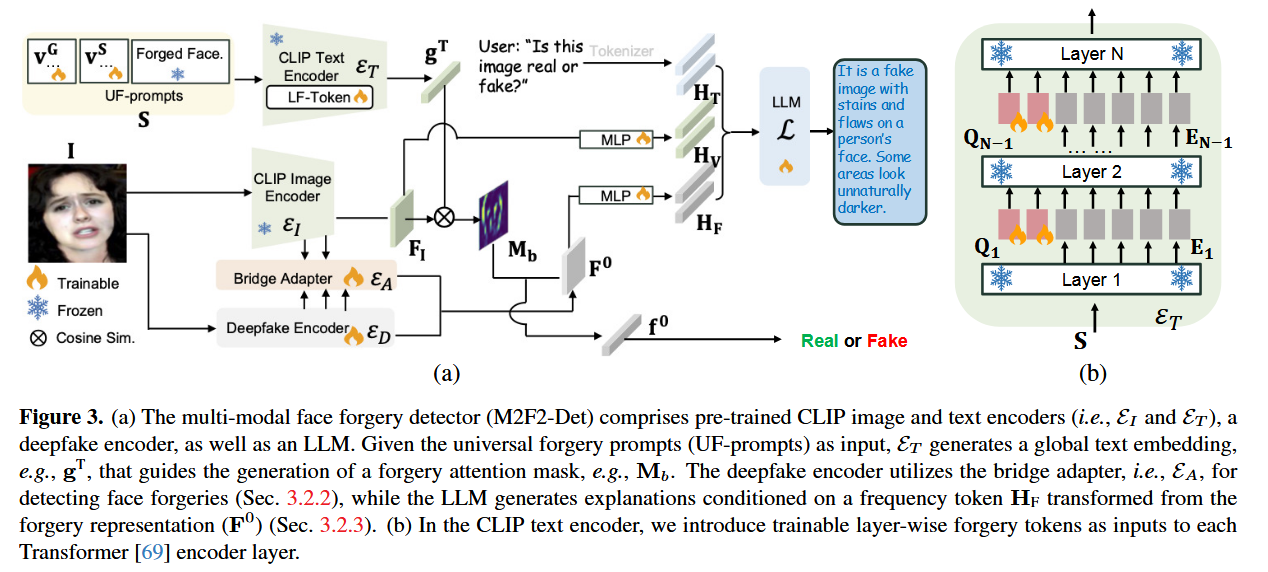
为了解决上述问题,作者提出了多模态可解释人脸伪造检测器(M2F2-Det),其创新点包括:
- 同时输出伪造判别分数与自然语言解释;
- 通过“Forgery Prompt Learning (FPL)”优化 CLIP 的提示学习,使其更好适应伪造检测;
- 引入“Bridge Adapter”结构,将 CLIP 图像编码器与 LLM 连接,实现检测特征与文本解释的联动。
本文提出的方法
第一阶段:先让模型学会“判断真假”
**训练目标:**让模型具备“识别真假”的能力,即判断一张人脸图像是真实还是伪造。
训练方式:
- 输入图像送入两个通道:
- 伪造检测器(ED):捕捉局部伪造细节(如边缘模糊、皮肤纹理异常)。
- CLIP 图像编码器(EI):提取整体语义特征;
- **文本编码器(ET)**使用“伪造提示学习模块(FPL)”生成专门的文字提示,用来指引模型关注可疑区域;
- 模型据此生成伪造注意力图(Mb),高亮伪造迹象;
- 桥接模块(EA)将 EI 与 ED 的特征融合,得到特征图 F₀;
- 经过卷积和池化操作后,提取出最终的伪造向量 f₀;
- 分类头根据 f₀ 输出真假结果。
**冻结策略:**冻结 CLIP 与 LLM 主体参数,仅训练 ED 与 FPL 的可学习提示
第二阶段:训练视觉到语言的桥接(Align 阶段)
**训练目标:**让模型知道如何把检测到的伪造特征(视觉特征)对齐到语言模型能理解的形式。
训练流程:
- 将 F₀ 通过一个小型 MLP 网络转化为伪造特征 token(HF);
- 将 CLIP 图像输出转换成视觉 token(HV);
- 让 MLP 学会把 HF 和 HV 映射到 LLM 能理解的语言空间。
**冻结策略:**冻结 CLIP、ED、LLM 主体,只训练 MLP 对齐层。
第三阶段:让模型学会“说出理由”(解释生成)
**训练目标:**让 LLM 根据视觉特征生成自然语言解释
eg:“这张脸是伪造的,因为皮肤光泽不自然,嘴角区域存在模糊。”
训练流程:
- 输入 HV(视觉 token)、HF(伪造 token)与文本问题(HT,如“Is this image real or fake?”);
- LLM 输出解释性文本 XA;
- 模型通过最大化概率 p(XA | HV, HF, HT) 学习生成准确流畅的说明;
- 使用 LoRA 进行高效微调,仅更新 LLM 的一小部分参数。
**冻结策略:**冻结 CLIP 与检测主干,只微调:对齐的 MLP 层,LLM 的部分参数(LoRA)
阅读总结
不足
- **在部分数据集上表现不稳定:**虽然在 FF++、Celeb-DF 等主流数据集上表现出色,但在 DFD 数据集上性能落后于 AUNet。
原因:AUNet 直接利用了“面部动作单元(Action Units)”等更细粒度的人脸动态特征,而 M2F2-Det 目前的 FPL 模块主要集中在图像静态纹理。
- **解释模块对外部数据依赖强:**第二、三阶段训练需要使用问答型解释数据集(DD-VQA),才能让模型学会“听懂视觉信息并生成语言解释”。这意味着在其他领域或新的伪造类型上迁移困难。
改进方法
-
**加入动态特征:**在视觉端引入 面部动作单元检测(Facial Action Units) 或 视频时序特征,使模型不仅关注静态伪造纹理,也能检测动态不一致。
-
**采用蒸馏:**离线用强大语言模型给少量图像生成解释,做人审+过滤后当老师,蒸馏到你的小LLM(LoRA)。