Language-guided Hierarchical Fine-grained Image Forgery Detection and Localization
英文题目:《Language-guided Hierarchical Fine-grained Image Forgery Detection and Localization》
中文题目:《语言引导的分层细粒度图像伪造检测与定位》
论文作者:Xiao Guo,Xiaohong Liu,Iacopo Masi,Xiaoming Liu
发布于:IJCV
发布时间:2025-12-10
级别:CCF-A
摘要
CNN 合成和图像编辑领域生成的图像的伪造属性差异很大,这种差异使得统一的图像伪造检测和定位 (IFDL) 具有挑战性。为此,我们提出了一种用于 IFDL 表示学习的分层细粒度公式。具体而言,我们首先用不同级别的多个标签表示被篡改图像的伪造属性。然后,我们利用它们之间的层次依赖关系在这些级别上进行细粒度分类。因此,该算法能够学习全面的特征和不同伪造属性固有的层次结构,从而改进 IFDL 表示。在本研究中,我们提出了一种语言引导的分层细粒度 IFDL,记为HiFi-Net++。具体来说,HiFi-Net++ 包含四个组件:多分支特征提取器、语言引导的伪造定位增强器,以及分类和定位模块。多分支特征提取器的每个分支学习在一个级别上对伪造属性进行分类,而定位模块和分类模块分别分割像素级伪造区域并检测图像级伪造。此外,语言引导的伪造定位增强器 (LFLE) 包含通过对比语言图像预训练 (CLIP) 学习的图像和文本编码器,用于进一步丰富 IFDL 表示。LFLE 将专门设计的文本和给定图像作为多模态输入,然后生成视觉嵌入和操作得分图,用于进一步提升 HiFi-Net++ 操作定位性能。最后,我们构建了一个分层细粒度数据集,以方便我们的研究。我们通过使用不同的基准测试,在 IFDL 和伪造属性分类任务上证明了我们方法的有效性。
本文聚焦的问题
这篇论文试图解决的是图像伪造检测和定位(Image Forgery Detection and Localization, IFDL)的问题,特别是在CNN合成和图像编辑领域中统一检测和定位伪造图像的挑战。具体来说,论文面临的挑战包括:
- 不同伪造方法产生的图像在伪造属性上存在较大差异:这些差异使得开发一个能够同时处理CNN合成和图像编辑领域伪造图像的统一算法变得困难。
- 需要对伪造图像的属性进行细粒度的表示学习:为了捕捉不同伪造方法之间的复杂属性,论文提出了一种层次化的细粒度表述,通过在不同层级上对伪造属性进行分类,来学习伪造图像的表示。
- 提高对小范围操纵区域的定位性能:在实际应用中,伪造图像可能只涉及图像的小部分区域,提高对这些小范围操纵区域的检测和定位性能是必要的。
- 提升算法的泛化能力:为了使算法能够在实际生活中有效,需要提高其对未见伪造类型的泛化能力。
为了解决这些问题,论文提出了一种名为HiFi-Net++的算法,该算法包含多个组件,如多分支特征提取器、语言引导的伪造定位增强器、分类和定位模块。此外,论文还构建了一个层次化的细粒度数据集(HiFi-IFDL)来促进相关研究,并在多个基准测试上验证了所提方法的有效性。
本文提出的方法
论文通过提出一个名为HiFi-Net++的算法来解决图像伪造检测和定位(IFDL)的问题。具体来说,HiFi-Net++通过以下几个关键组件和步骤来解决这个问题:
1. 层次化细粒度表述学习(Hierarchical Fine-grained Formulation)
- 多标签表示:首先,论文提出用多个不同层级的标签来表示被操纵图像的伪造属性。
- 细粒度分类:然后,利用这些层级的层次依赖性执行细粒度分类,从而鼓励算法学习综合特征和不同伪造属性之间的固有层次结构。
2. HiFi-Net++算法
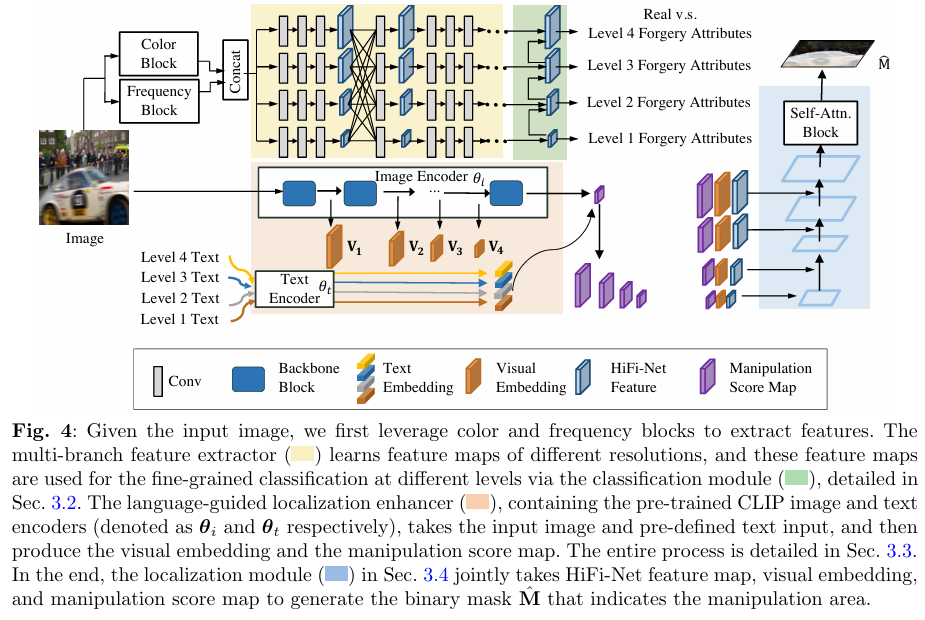
HiFi-Net++包含以下几个主要组件:
- 多分支特征提取器:每个分支学习一个层级的伪造属性分类。
- 语言引导的伪造定位增强器(LFLE):利用对比语言-图像预训练(CLIP)学习到的图像和文本编码器,通过特别设计的文字和给定图像作为多模态输入,生成视觉嵌入和操作得分图,以进一步改善操纵定位性能。
- 分类和定位模块:分别负责图像级别的伪造检测和像素级别的伪造区域分割。
3. 数据集构建
- 层次化细粒度数据集(HiFi-IFDL):为了促进层次化细粒度IFDL研究,作者构建了一个新的数据集,其中包含了13种伪造方法,并在伪造类别上引入了层次结构,以支持各种伪造属性的分类器学习。
4. 训练和推理
- 在训练阶段,每个分支针对相应层级的分类进行优化,并使用不同的损失函数来训练模型。
- 在推理阶段,HiFi-Net++接受输入图像和预定义的文本输入,生成伪造掩码,并预测不同层级的伪造属性。
5. 语言引导的伪造定位增强器(LFLE)
- 文本输入构建:使用伪造属性名称和预定义模板创建文本输入。
- 架构:预训练的CLIP图像编码器提供视觉嵌入,然后通过预训练的CLIP文本编码器获得相应的文本嵌入。这些文本嵌入与视觉特征一起生成2D操纵得分图,作为辅助信号帮助定位操纵区域。
通过这些方法,HiFi-Net++能够有效地检测和定位伪造图像,并在多个基准测试中展示了其优越的性能。
阅读总结
不足与改进方法
- 适应性分支控制机制:论文中提到,HiFi-Net++的多分支特征提取器可能在检测某些类型的伪造图像(例如DALLE-3)时效果不佳。未来的研究可以探索开发一种适应性分支控制机制,根据输入图像动态调整分支数量,以提高模型的整体性能。
- 跨模态伪造检测:探索跨模态伪造检测,可以结合图像和文本信息来检测和定位伪造内容。