SIDA: Social Media Image Deepfake Detection, Localization and Explanation with Large Multimodal Model
英文题目:《Social Media Image Deepfake Detection, Localization and Explanation with Large Multimodal Model》
中文题目:《SIDA:基于大型多模态模型对社交媒体图像深度伪造检测、定位与解释》
论文作者:Zhenglin Huang,Jinwei Hu,Xiangtai Li,Xiangtai Li,Xingyu Zhao,Bei Peng,Baoyuan Wu,Xiaowei Huang,Guangliang Cheng
发布于:CVPR
发布时间:2025-06
级别:CCF-A
摘要
生成模型在创建高度逼真图像方面的快速进展, 对错误信息传播构成了重大风险。例如,当合成图像在社交媒体上分享时,可能会误导大量受众并侵蚀对数字内容的信任,导致严重后果。尽管取得了一些进展,学术界尚未为社交媒体创建一个大型且多样化的 深度伪造检测数据集,也尚未设计出有效的解决方案 来应对这一问题。在本文中,我们介绍了社交媒体图像检测数据集(SID-Set),该数据集具有三个主要优势:(1)大规模,包含300KAI生成/篡改和真实图像, 并具有全面的标注,(2)广泛多样性,涵盖各种类别的完全合成和篡改图像,(3)更高的逼真度,图像通过仅 视觉检查几乎无法与真实图像区分。此外,利用大型多模态模型的卓越能力,我们提出了一种新的图像深度伪造检测、定位和解释框架,命名为SIDA(社交媒体图像检测、定位和解释助手)。SIDA不仅能够辨别图像的真实性,还能通过掩码预测描绘篡改区域,并提供模型判断标准的文本解释。与SID-Set和其他基准 上的最先进深度伪造检测模型相比,大量实验表明, SIDA在多样化设置中实现了卓越性能。
本文聚焦的问题
1. 数据集多样性不足
- 现状问题: 现有数据集主要集中在“人脸图像伪造”场景,忽视了社交媒体中大量存在的非人脸图像伪造问题。
- 具体缺陷:
- 多为简单场景图像,缺乏社交媒体的复杂背景;
- 使用的生成技术较为过时,伪造痕迹明显,难以代表真实威胁;
- 缺少利用最新生成式AI方法、专门针对社交媒体设计的大规模伪造数据集。
2. 数据集覆盖面有限
- 现状问题: 多数数据集仅聚焦单一任务(如检测或定位),或针对特定生成/篡改方法。
- 理想目标:
- 应能同时涵盖检测 + 定位任务;
- 覆盖完全生成图像与编辑篡改图像两种伪造类型;
- 更贴近真实社交媒体内容的复杂性与多样性。
- 附加不足: 现有研究多关注模型分类结果,而忽视了模型决策背后的线索与依据。
文章聚焦于当前深度伪造检测与定位数据集“缺乏多样性与覆盖面”的双重问题,指出其难以反映真实社交媒体伪造的复杂性与最新生成技术的挑战,基于此本文构建SID‑Set数据集(目前规模最大、标注最全面的数据集,是迄今为止社交媒体深度伪造检测最大、最全面的数据集)。与表1中现有的数据集相比, SID‑Set通过提供更全面的高质量和多样化的图像,解决了多样性和生成技术过时的问题。
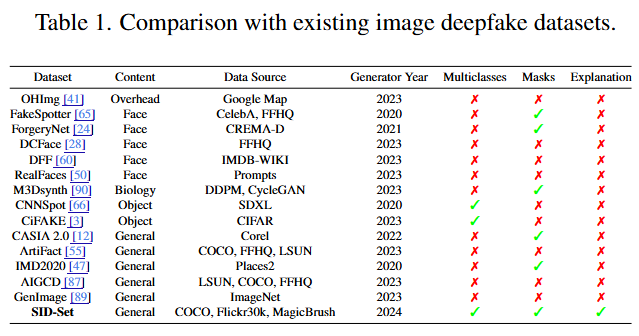
在此基础上,我们提出了一种新的基于视觉语言模型(VLMs)的深度伪造检测框架,命名为社交媒体图像检测、定位和解释助手(SIDA),该框架在SID‑Set上实现了最先进的 (SOTA)性能,并能有效地泛化到其他基准。
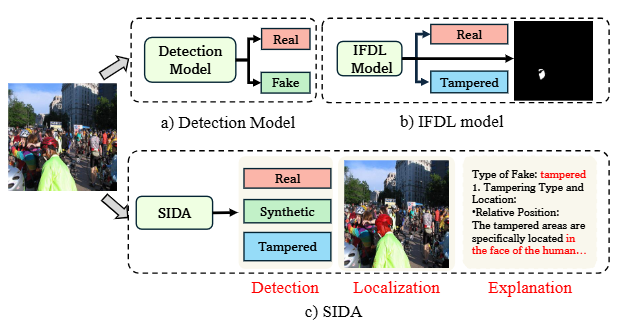
本文提出的方法
SID‑Set数据集创建
SID‑Set是一个包含真实图像、合成图像和恶意图像的数据集,反映了多样 化的现实场景。
我们的基准评估模型是否能够区分真实图像、合成图像和恶意图像,以及准确识别恶意图像中 的修改区域。
- 真实图像:来自OpenImagesV71,的10万张图像,涵盖了广泛的场景,反映了现实世界的多样性。
- 合成图像:通过FLUX[43],生成的10万张图像,专门设计用于挑战识别,因为它们具有高质量的逼真外观。
- 篡改图像:10万张篡改图像,其中特定对象或区域被替换或修改;
数据生成:为了生成高度逼真的合成图像,我们实验了多个开源的SOTA生成模型,例如FLUX[43], Kandinsky3.0 [1], SDXL [52], AbsoluteReality [42]以及其他模型,由每位人类专家对每个生成模型生成的1,000张图像进行评审后,FLUX脱颖而出,生成的图像极具说服力,对人类专家而言无法与真实图像区分。具体生成过程如下:
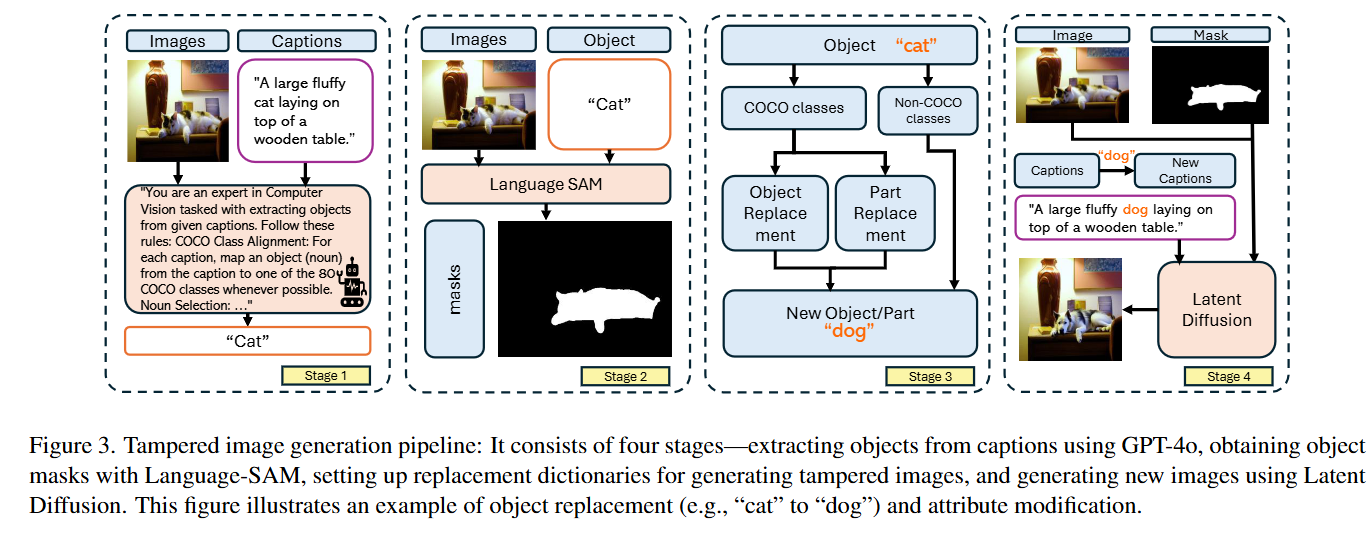
阶段 1:语义抽取(对象识别)
目的:确定要修改的对象是什么。
- 输入:真实图像 + 图像标题(例如“a big fluffy cat lying on a wooden table”)。
- 操作:GPT-4o 解析标题,抽取关键对象(如“cat”“table”),并映射到 COCO 类别。
- 输出:一个“图像–标题–对象”结构化记录(JSON)。
阶段 2:对象定位(生成掩码)
目的:精确定位要被替换或修改的区域。
- 工具:Language-SAM(结合自然语言提示的 SAM 模型)。
- 操作:根据上一步的对象名称,生成对应的像素级掩码 mask。
- 输出:mask 区域作为真实标签,用于后续编辑或定位训练。
阶段 3:替换/修改词典
目的:告诉模型“要把什么变成什么”。
- 操作:为每个对象定义可替换或可修改的语义规则。
- 完整替换(object replacement):如“dog → cat”;
- 属性修改(attribute edit):如“dog → happy dog”。
- 输出:替换字典(完整替换 + 局部修改)。
阶段 4:潜在扩散生成(图像重绘)
- 工具:Latent Diffusion(采用FLUX 模型)。
- 操作:
- 将标题替换为修改后的指令(如把“cat”改成“dog”);
- 使用掩码指导模型只在目标区域内重绘;
- 输出新的图像:得到一张在语义和像素上都与原图一致、但内容已被篡改的高逼真图。
SIDA检测
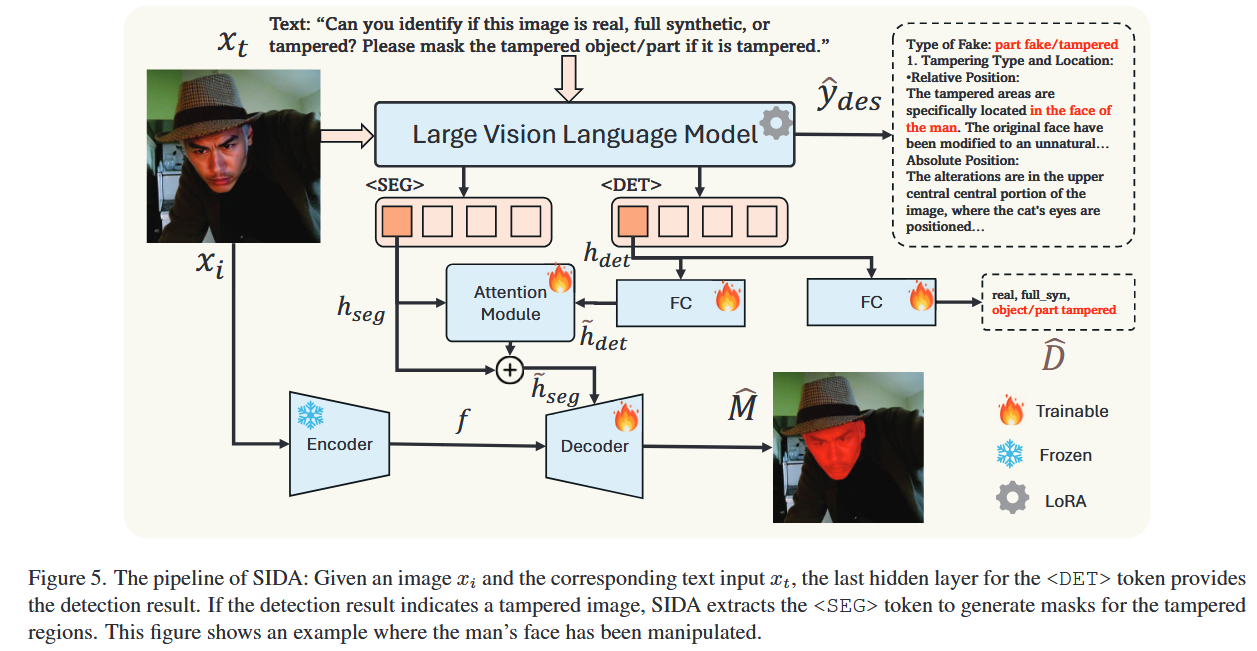
阶段一:输入阶段——让模型“看懂图与任务”
训练从输入开始。SIDA 同时接收一张图像和一个文字提示,例如:“请判断这张图是真实的、完全生成的还是被篡改的,并指出修改区域。”
阶段二:特征提取阶段
在多层 Transformer 交互中,模型输出一组多模态特征,其中两个特殊标记 <DET> 与 <SEG> 被用来提取不同任务的线索:
<DET>专注于图像真假判定的全局语义;<SEG>专注于局部空间特征,用于判断“哪里被改动”。
阶段三:检测与定位阶段——判断真假与圈出篡改
-
检测分支从
<DET>特征中学习三分类任务:真实、合成或篡改; -
定位分支从
<SEG>特征中生成像素级掩码,标出被改动的部分。
为了让两个任务互相协调,模型通过一个“多头注意力模块”把检测结果的语义特征注入分割分支。这样,检测分支学到的“哪里可疑”信息能指导分割分支更精确地画出伪造区域边界。
阶段四:解释生成阶段——让模型“讲清楚理由”
当模型完成真假判断与掩码定位后,还会生成一段自然语言解释。
例如,它会说出:“桌面反光与周围光照方向不一致,疑似被生成模型修改。”
这一阶段用 3,000 张带人工标注解释的图像样本来微调,使模型学会“说出推理依据”,让输出更透明、更可信
阶段四:联合训练阶段——多任务协同优化
SIDA 的训练共分两步:
-
主训练阶段:同时优化检测损失和定位损失。定位损失由二元交叉熵 (BCE) 与 Dice 损失加权组合构成,以平衡边界精度与掩码完整性。
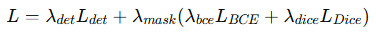
-
微调阶段:再加入解释损失,仅微调语言生成部分。最终总损失为:
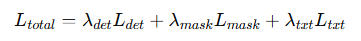
这种分阶段训练方式能让模型先学会“看出真假和改动”,再学会“说明理由”,达到检测、定位、解释三者兼顾
阅读总结
不足
- SIDA 构建在通用视觉语言模型 LISA 之上,但 LISA 在捕捉高保真伪造的“细微线索”方面不够敏感,例如光照不一致、纹理边缘平滑、微模糊等。这样将导致在一些复杂伪造场景中仍会漏检或定位不准确。
- SIDA 的检测与定位分支交互完全依赖一个单层多头注意力模块;一旦该模块退化或参数设置不当,整体性能会急剧下降。这样的话在新数据域(不同伪造模型或编辑类型)下,泛化性可能受限。
改进措施
1. 扩充并多样化训练样本
- 增加高难度伪造样本(如局部细节替换、跨模态融合、光照/几何微扰),提升模型在真实社交媒体伪造场景下的适应性。
- 扩充解释文本数据集,从 3,000 增加到更大规模,改进模型在“解释可理解性”方面的稳定性。
2.优化特征交互机制,降低单点依赖
- 将现有的单层注意力扩展为分层交互结构(Layer-wise Cross-Attention)或多路径信息融合(Dual-path Aggregation)。
- 增设轻量冗余通道,例如门控融合(Gated Fusion)或残差并联分支,保证特征互补性。