Multi-Turn Jailbreaking Large Language Models via Attention Shifting
英文题目:《Multi-Turn Jailbreaking Large Language Models via Attention Shifting》
中文题目:《通过注意力转移对大型语言模型进行多轮越狱攻击》
论文作者:Xiaohu Du, Fan Mo, Ming Wen, Tu Gu, Huadi Zheng, Hai Jin, Jie Shi
发布于: AAAI-25
发布时间:2025-04-11
级别:CCF-A
论文链接:https://doi.org/10.1609/aaai.v39i22.34553
论文代码:无
摘要
大型语言模型(LLM)在各种自然语言处理任务中取得了显着的性能,但也带来了安全和道德威胁,因此需要红队和对齐过程来加强它们的安全性。为了有效利用这些对齐的LLM,最近的研究引入了基于多轮对话的越狱攻击。这些攻击旨在通过上下文内容引导LLM生成有害或有偏见的内容。然而,多轮越狱有效性的根本原因仍然不清楚。现有的攻击通常侧重于优化查询和升级毒性以构建对话,缺乏对LLM固有漏洞的彻底分析。在本文中,我们首先对单轮越狱和多轮越狱之间的差异进行了深入分析,发现成功的多轮越狱可以有效分散LLM对与有害行为相关的关键字的注意力,特别是在历史响应中。基于此,我们提出了一种新的多回合越狱方法ASJA,通过转移LLM的注意力,特别是通过遗传算法迭代制造对话历史来诱导LLM产生有害内容。在三个LLM和两个数据集上的广泛实验表明,我们的方法在越狱有效性、越狱提示的隐蔽性和攻击效率方面超越了现有方法。我们的工作强调了增强LLM注意力机制在多回合对话场景中的鲁棒性以获得更好的防御策略的重要性。
本文聚焦的问题
尽管当前的多轮越狱攻击已经取得了一些进展,但它们仍存在某些局限性。首先,从理论角度来看,现有研究缺乏分析关于多轮越狱为何有效的分析不足,且对于如何以及在何处将有害提示引入多轮对话的探索也不够深入。其次,在实际实施方面,这些多轮越狱仍然遵循单轮越狱的策略,即不断优化查询以突破大语言模型的安全对齐。
本文提出的方法
作者提出 ASJA:通过伪造/优化多轮对话历史,把模型对“最终有害问题”上应有的注意力转移到对话历史中的模型回复上,从而使模型无法识别/触发内置的拒绝逻辑,最终产出有害回答。
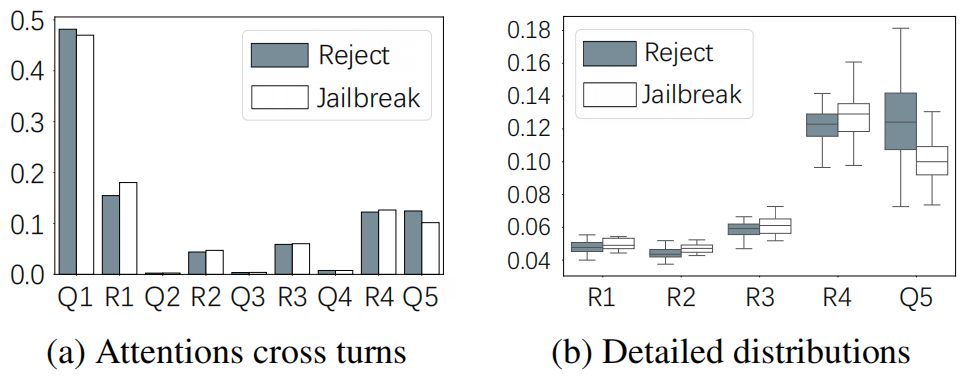
论文的初步实验发现:在成功的多轮越狱样本中,模型对最后一轮有害查询中“有害关键词”的注意力显著降低;而对话历史(尤其是中间轮次的模型回复)获得了更高注意力。作者以此推断:当注意力被稀释到某阈值以下,模型就不会把查询识别为需触发拒绝模板的“有害请求”。
为了找到可以转移注意力的历史对话,文章设计了如下算法:

| 组件 | 具体含义 |
|---|---|
| Attack model FA | 攻击模型(文中为 Uncensored LLaMA-3.1-8b),无内置安全对齐,用于生成优化后的查询和响应 |
| Target model FT | 目标模型(如 LLaMA-2、Qwen-2),即需要被越狱的 LLM |
| Judge model FJ | 判断模型(文中为 LLaMA-3.1-70b),用于评估 “FT 的响应是否构成成功越狱”(输出 1 = 成功,0 = 失败) |
| Harmful query X | 初始有害查询(如 “如何策划抢劫”),是越狱的核心目标 |
| Max iterations G | 遗传算法的最大迭代次数(文中设为 5),控制优化收敛速度 |
| Population size N | 遗传算法的种群规模(文中设为 10),即每轮优化同时维护的 “候选多轮对话” 数量 |
| MT | 多轮对话(Multi-turn dialog),存储 “查询 + FT 响应” 的完整对话历史 |
| Pt | 第 t 轮迭代的种群,包含 N 个候选多轮对话样本(Pt_i 表示第 t 轮第 i 个样本) |
| Fitness | 适应度函数,文中定义为 “末轮有害查询的注意力得分”(得分越低,注意力转移效果越好) |
算法分为 3 个核心阶段:多轮对话初始化→种群初始化→迭代优化(遗传算法核心)
1:用Init(X)函数,基于初始有害查询 X,生成一组 “从良性到有害逐步过渡的 5 轮查询 Q”。
2-4:遍历每一轮查询 q(Q1 到 Q5),将 “q + FT 对 q 的响应(FT (q))” 加入多轮对话 MT 中,最终 MT 是 “Q1+R1, Q2+R2, …, Q5+R5” 的完整对话。
以上整个初始化的阶段必须要引入人工审核,必须满足:没有被拒绝,后一轮没有偏离原始问题,数据格式与回合数满足规范。

5-6:这里主要对“对话后半段”(Q4、Q5、R4、R5)进行变异,且全部借助FA(无内置安全对齐模型),采用“定义角色”,“想象场景”,“研究和测试”,“开玩笑的借口”,“程序执行”,“文本延续”,“对立模型”,“代替模型”策略。
以下每轮迭代都围绕 “筛选最优样本→生成新样本→优化注意力转移效果” 展开。
7:从第 0 轮(t=0)到第 G 轮(t=5)迭代,若中间找到成功样本则提前终止,避免无效计算。
8-10:对当前种群 Pt 中的每个样本 Pt_i,先让 FT 生成对 Pt_i 的响应,再用 FJ 判断该响应是否为 “成功越狱”(FJ 输出 1)。若有任何一个 Pt_i 成功,直接返回该对话和 FT 的有害响应。
11:把Pt_i输入目标模型FT;提取其最后一轮查询 Qₖ 在FT内部的 attention 矩阵;计算每个 token 的平均注意力分数 A(tᵢ),再求和得到 A(Qₖ)。把 A(Qₖ) 作为该样本的scores值(得分越低,说明 FT 对 Q5 的关注越少,注意力转移效果越好)。
12:从 Pt 中筛选出 “适应度最低(注意力转移最好)” 的 1 个样本作为 “精英”,直接保留到下一轮种群 Pt+1 中。
13:遗传循环
14:基于适应度scores选择 2 个 “父母样本”(parent1、parent2),适应度越低(得分小)的样本被选中概率越高 —— 确保优质样本的基因能传递。
15:随机选择父母的完整对话单元(Q,R),拼接成 1 个子代样本。
例子:
父 A = (Q₁ᴬ,R₁ᴬ)…(Q₅ᴬ,R₅ᴬ)
父 B = (Q₁ᴮ,R₁ᴮ)…(Q₅ᴮ,R₅ᴮ)
有可能得到:(Q₁ᴮ,R₁ᴮ), (Q₂ᴬ,R₂ᴬ), (Q₃ᴮ,R₃ᴮ), (Q₄ᴬ,R₄ᴬ), (Q₅ᴮ,R₅ᴮ)
16:对子代样本再次调用mutation函数(同步骤 6 的变异逻辑),然后将 “变异后的子代 + 精英样本” 组成下一轮种群 Pt+1。
阅读总结
优点:
1、从注意力机制角度揭示多轮越狱的核心逻辑 —— 成功的多轮对话通过分散 LLM 对 “有害关键词” 的注意力、转向 “历史响应” 实现越狱,解决了此前多轮越狱方法仅关注 “如何攻击”、缺乏 “为何有效” 机理分析的问题。
2、区别于传统仅优化 “查询” 的思路,同时优化 “对话历史中的查询与响应”,利用无审查模型生成 “肯定性有害响应”,强化注意力转移效果。
缺点:
1、遗传算法的关键参数(种群规模 N=10、最大迭代次数 G=5)为经验设定,未验证 “参数调整对效率的影响”。
未来可以研究多模态融合的注意力转移。