RAIDX: A Retrieval-Augmented Generation and GRPO Reinforcement Learning Framework for Explainable Deepfake Detection
英文题目:《RAIDX: A Retrieval-Augmented Generation and GRPO Reinforcement Learning Framework for Explainable Deepfake Detection》
中文题目:《RAIDX:一种用于可解释深度伪造检测的检索增强生成和GRPO强化学习框架》
论文作者: Tianxiao Li, Zhenglin Huang, Haiquan Wen, Yiwei He, Shuchang Lyu, Baoyuan Wu, Guangliang Cheng
发布于:MM ’25: Proceedings of the 33rd ACM International Conference on Multimedia
发布时间:2025-05-20
级别:CCF-A
论文链接:https://doi.org/10.1145/3746027.3754798
论文代码:暂无
摘要
人工智能生成模型的快速发展使得超逼真图像的创建成为可能,但也因此引发了广泛的虚假信息传播,带来了伦理风险。目前,深度伪造检测方法主要分为人脸检测器和通用人工智能生成检测器,但由于将检测过程视为分类任务而缺乏解释,因此缺乏透明度。虽然一些基于逻辑逻辑模型(LLM)的方法能够提供可解释性,但它们存在分析粒度过粗和依赖劳动密集型标注等问题。本文提出了一种名为RAIDX(检索增强图像深度伪造检测与可解释性)的新型深度伪造检测框架,该框架融合了检索增强生成(RAG)和组相对策略优化(GRPO),旨在提高检测精度和决策可解释性。具体而言,RAIDX利用RAG整合外部知识以提高检测精度,并采用GRPO自动生成细粒度的文本解释和显著性图,从而无需大量的人工标注。在多个基准测试平台上进行的实验表明,RAIDX 能够有效识别真假图像,并在文本描述和显著性图中提供可解释的分析结果,在提升深度伪造图像识别透明度的同时,实现了最先进的检测性能。RAIDX 是首个将 RAG 和 GRPO 相结合的统一框架,解决了准确性和可解释性方面的关键缺陷。我们的代码和模型将公开提供。
本文聚焦的问题
当前的深度伪造检测技术主要存在两大核心问题:
- 缺乏可解释性 现有主流方法多将检测视为一个二分类任务(真实/伪造),模型虽然能给出结果,但无法解释“为什么判定为伪造”。这导致检测过程呈现黑箱化,用户无法信任或验证模型决策依据。即使一些基于掩码(mask)的检测方法尝试同时给出定位结果,仍停留在粗粒度层面,难以提供细致、语义化的解释**。
- 依赖大量人工标注 可解释性方法(如基于LLM或VLM的模型)通常需要大量人工掩码或文本说明标注,这在实际场景中代价高昂且难以扩展,限制了模型在新型伪造类型上的应用。
本文提出的方法
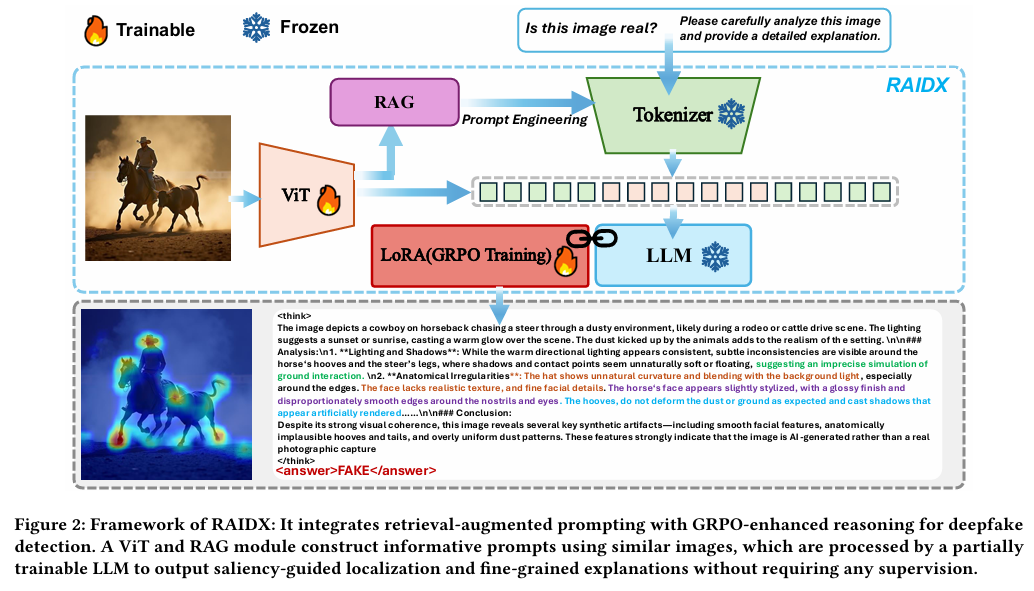
RAIDX 的整体架构由四个核心模块组成:
Vision Transformer (ViT): 提取输入图像的高层视觉特征,这些特征同时流向两个路径:
- 一部分送入 RAG 模块 用于相似图像检索;
- 另一部分与文本 token 一起输入到 语言模型 (LLM),参与多模态推理。
RAG 检索增强生成模块: RAG 模块在 FAISS 向量索引库中检索与输入图像最相似的样本,并统计其“真实/伪造”分布,然后将这些信息以自然语言形式嵌入提示语(prompt)中,如:
“在最相似的 10 张图像中,7 张为真实,3 张为伪造,请综合这些信息判断当前图像。”
这让模型在判断时具备“类比推理”的能力,而不仅依赖单一输入,从而提高检测的鲁棒性和事实支撑。
大语言模型(LLM + LoRA 适配器): LLM 负责推理与解释生成。模型分两阶段输出:
阶段 :详细分析图像伪造线索,如光照不一致、阴影漂浮、边缘平滑等;阶段 :给出最终“真实/伪造”结论。 同时,LLM 会根据 ViT 的注意力权重生成显著性热图(Saliency Map),直观显示模型关注的可疑区域。
GRPO 强化学习模块: 在训练阶段,使用 Group Relative Policy Optimization (GRPO) 对 LoRA 参数进行优化,使模型学会在无人工标注的情况下自我改进推理逻辑。GRPO 通过奖励机制鼓励:
- 正确判断(Accuracy Reward);
- 结构化输出(Format Reward,如使用
/ 块)。
这种方式让模型逐渐具备稳定的“思维链式推理”能力。
阅读总结
不足
- RAG 侧的局限:当前的检索增强策略仍有优化空间,尤其是如何用极低成本把“未见过的新生成模型”的数据快速纳入外部知识库(例如每个新模型只生成 5–10 个样本),以便快速适配分布漂移与新伪造风格。
- 任务覆盖不足:RAIDX 主要针对“整幅合成图”检测,虽然能给出显著图,但尚未处理局部篡改(tampered)的图像取证与定位问题,这限制了其在更复杂真实场景中的适用性。
改进措施
- RAG 在线自适应与去偏:把 FAISS 索引做成可在线增量更新(新生成模型来一批就插一批),利用轻量微调或自适应加权机制,使模型无需重新训练即可识别新型伪造样式。
- 增加一个轻量级的 局部篡改检测模块(Tamper Head),让模型在判断真假之外,还能标出可疑区域。这个模块利用模型自身的注意力热图或部分伪造图生成“伪标签”来学习,从而让系统具备识别和定位局部篡改的能力。