Rethinking Image Forgery Detection via Soft Contrastive Learning and Unsupervised Clustering
英文题目:《Rethinking Image Forgery Detection via Soft Contrastive Learning and Unsupervised Clustering》
中文题目:《通过软对比学习和无监督聚类重新思考图像伪造检测》
论文作者:Haiwei Wu; Yiming Chen; Jiantao Zhou; Yuanman Li
发布于: IEEE Transactions on Dependable and Secure Computing
发布时间:2025-06-25
级别:CCF-A
摘要
图像伪造检测的目标是识别并定位图像中的伪造区域。现有的大多数伪造检测算法通过分类问题来区分伪造像素和原始像素。然而,伪造像素与原始像素的定义仅在单个图像内部相对,例如,图像A中的伪造区域在其原始图像B中可能是原始的(拼接伪造)。这种相对定义被现有方法严重忽视,导致不同图像中的伪造(或原始)区域被不必要地归为同一类别。为了解决这一难题,我们提出了基于软对比学习和无监督聚类的新型、简单而有效的图像伪造检测方法——伪造对比聚类(FOCAL,FOrensic ContrAstive cLustering)。具体来说,FOCAL
1)设计了一种软对比学习(SCL,soft contrastive learning),以图像为单位监督高级伪造特征的提取,明确体现了上述相对定义;
2)采用即时无监督聚类算法(而非训练好的算法)将学习到的特征聚类为伪造和原始类别,进一步减少了训练数据对不同图像的影响;
3)通过简单的特征级连接来提升检测性能,无需重新训练。
本文聚焦的问题
这篇文章聚焦于解决**图像伪造检测(Image Forgery Detection)**中的一个关键问题:现有方法在定义“伪造”和“ pristine”(未被篡改)像素时,忽略了这些定义在单张图像内的相对性。例如,一张图像中的伪造区域可能在另一张图像中是未被篡改的区域,这种相对性被现有方法严重忽视,导致分类方法在跨图像混合伪造和未被篡改区域时出现标签冲突,进而影响检测性能。
本文提出的方法
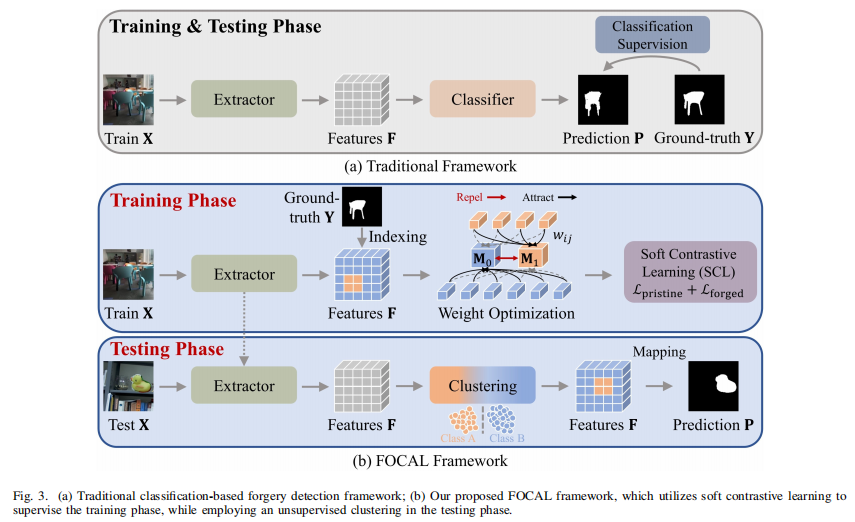
软对比学习(SCL)模块(训练阶段)
目的:解决跨图像 “forged / pristine” 标签语义不一致,导致监督噪声的问题。
做法:每张图像单独优化(image-by-image),学习“特征可分性”,而不是直接学习mask。
给定 backbone 抽取的特征 ,引入 soft assignment 权重 (像素 i 属于类别 j 的程度)与类别中心 :
通过交替求解迭代更新:
最终用改造后的 Soft Contrastive Loss(类似NCE)监督 backbone:
- 无监督聚类模块
该模块负责在测试阶段将提取的特征划分为“伪造”或“原始”区域,其作用是避免使用训练好的分类器带来的跨图像泛化偏差,实现图像级别的独立判断。具体做法是:对每张图像提取的特征使用无监督聚类算法(如HDBSCAN)进行在线聚类,假设伪造区域通常较小,因此将元素最多的簇标记为原始区域,其余簇合并为伪造区域,从而生成最终的伪造定位掩码,整个过程无需训练参数、不依赖训练数据,具有较强的泛化能力和适应性。
阅读总结
-
优点:
-
指出并验证了“伪造/原始标签跨图冲突”这一被长期忽视的本质缺陷。
-
训练只做“对比特征”,测试只做“聚类”,无需分类头,跨域泛化能力极强。
-
-
缺点:
- 核心假设脆弱:聚类阶段“最大簇=原始”在大面积伪造或全图伪造时直接失效,导致漏检与误检激增。
- 伪造类型敏感:对GAN整图生成、深度人脸合成等无局部不一致性的伪造,特征判别力天然下降。