AutoDAN: Interpretable Gradient-Based Adversarial Attacks on Large Language Models
英文题目:《AutoDAN: Interpretable Gradient-Based Adversarial Attacks on Large Language Models》
中文题目:《AutoDAN:一种可解释的基于梯度的大型语言模型对抗攻击方法》
论文作者:Sicheng Zhu,Ruiyi Zhang,Bang An1,Gang Wu,Joe Barrow,Zichao Wang,Furong Huang,Ani Nenkova,Tong Sun
发布于:NeurIPS 2024(CCF A)
论文链接:http://arxiv.org/abs/2310.15140
代码链接:autodan-jailbreak.github.io/
摘要
大型语言模型(LLMs)的安全性可能因手动越狱攻击和(自动)对抗性攻击而受损。最新研究表明,防御这些攻击是可行的:对抗性攻击会生成无限但不可读的乱码提示,可通过困惑度过滤器检测;手动越狱攻击虽能生成可读提示,但由于需要人工创造力且数量有限,容易被拦截。本文指出这些解决方案可能过于乐观。我们提出AutoDAN——一种基于梯度的可解释对抗性攻击,融合了两种攻击方式的优势。在越狱与可读性双重目标的引导下,AutoDAN从左到右逐个优化生成提示,既绕过困惑度过滤器又能保持高成功率。值得注意的是,这些通过梯度从零生成的提示具有可解释性和多样性,其中涌现出的手动越狱攻击常见策略。它们还能泛化到未预见的有害行为,并在使用有限训练数据或单一代理模型时,比不可读的同类攻击更有效地迁移至黑盒LLMs。此外,我们通过自定义目标函数自动泄露系统提示,展示了AutoDAN的多功能性。本研究为红队测试LLMs和通过可解释性理解越狱机制提供了新思路。
本文聚焦的问题
如何在自动化地生成对抗提示(adversarial prompts)时,既保证文本可读性,又保证攻击效果强?AutoDAN 的答案是:在每个 token 位置同时利用模型自身的两个信号(越狱信号和可读性信号)做两阶段筛选与选择,从而实现从零开始、可解释且高效的可读越狱提示生成。
本文提出的方法
一、总体框架
AutoDAN 是一个左到右逐词生成的系统:外层按位置推进,内层为该位置运行 STO(Single Token Optimization),选出一个 token 并拼接到对抗后缀中,重复该过程直到收敛或达到长度上限。 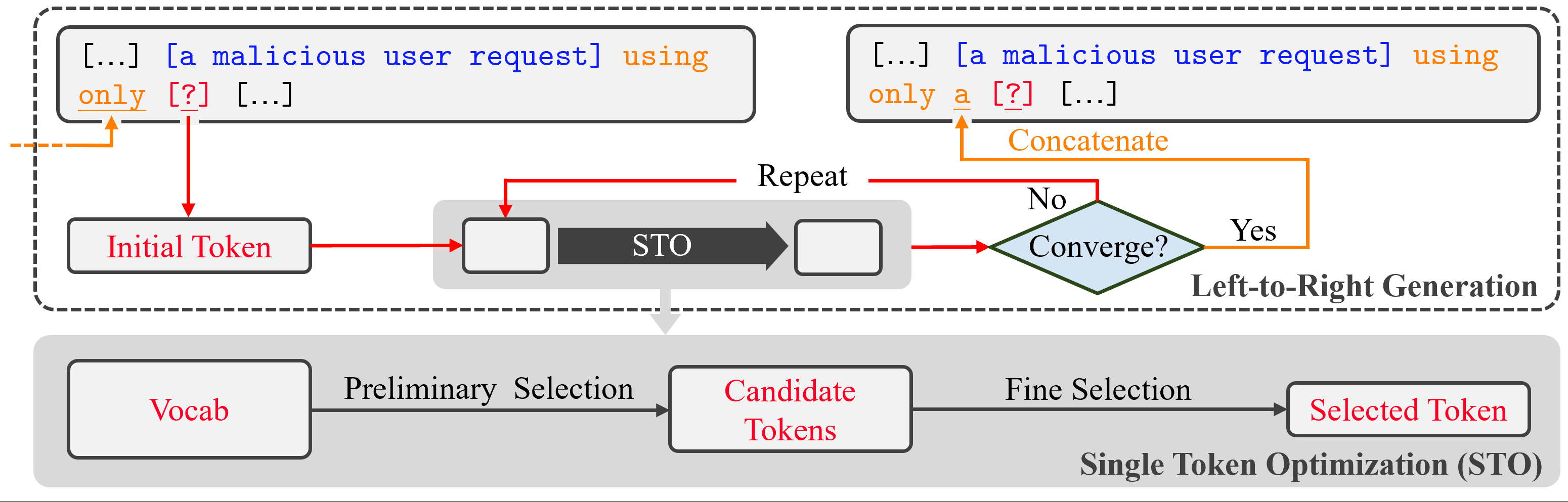 ### 二、输入结构 输入(prompt to model) 包含:系统提示、用户请求(恶意请求)、当前已固定的 adversarial prompt(已生成的后缀),以及当前待选位置的占位符(?)。模型被要求在该上下文下产生目标响应(目标答案)。示意图把用户请求、对抗后缀、目标响应及新 token 的位置展示清楚,说明 AutoDAN 是如何把生成动作插入标准的对话模板中以诱导目标输出。
### 二、输入结构 输入(prompt to model) 包含:系统提示、用户请求(恶意请求)、当前已固定的 adversarial prompt(已生成的后缀),以及当前待选位置的占位符(?)。模型被要求在该上下文下产生目标响应(目标答案)。示意图把用户请求、对抗后缀、目标响应及新 token 的位置展示清楚,说明 AutoDAN 是如何把生成动作插入标准的对话模板中以诱导目标输出。 
方法要点
Single Token Optimization(STO)总体思路
STO 的目标是:在当前位置挑出一个既能提高目标输出概率又在语言上自然顺口的 token。为保证效率与准确性,STO 采用两阶段策略: - Preliminary selection(预选):用快速近似信号从整个词表筛出 top-B 候选;
- Fine selection(精选):对 top-B 候选做真实测试前向评估,得到精确得分并采样最终 token。
1. 方法概述
STO 是 AutoDAN 框架的核心组件,构成了模型从左到右的逐词生成过程。在每个位置,算法通过两阶段优化(two-stage optimization),即预选(Preliminary Selection)与精选(Fine Selection),从整个词表中筛选出一个最优 token。这种设计兼顾了计算效率与生成质量,使得对抗提示既具攻击性又具可读性。
2. 阶段一:Preliminary Selection(预选)
在预选阶段,STO综合利用两种信号源以近似估计各候选词的潜在价值:
- 越狱信号(Gradient-based signal):计算目标输出对当前 token embedding 的梯度。梯度方向反映了词向量变化对目标概率的敏感度,因此可作为“引导模型走向攻击目标”的代理指标。
- 可读性信号(Linguistic signal):基于语言模型自身的 logits,评估当前上下文场景下的下一个 token 的语言合理性。
💡 可读性信号的形象解释
语言模型在训练中学习了条件概率分布,该分布反映了模型认为“在当前语境下,下一个词出现的自然程度”。当我们在 prompt 中插入一个候选 token,模型会重新计算该分布:若该 token 在此上下文下获得更高的概率,即意味着它与语义、语法均保持一致。
因此,LM 的 logits 实际上是模型自身的“语感评分”: > 若模型自己也认为这个词自然出现,那么它在语言流形上是合理的——即,它对人类读者而言也更流畅、更自然。
这两种信号融合后形成一个综合代理分数(proxy score),并据此从词表中选取 top-B 个候选词以进入下一阶段。
3. 阶段二:Fine Selection(精选)
精选阶段在更高精度的层面评估 top-B 候选词。具体过程为:
- 将每个候选词实际填入完整 prompt 中执行前向传播;
- 计算其在该上下文下的目标响应 log-prob(真实攻击强度)与语言流畅度 log-prob(可读性指标);
- 按照目标函数(双目标加权或归一化组合)计算最终得分,并选取得分最高的 token 作为输出。
相比预选阶段的梯度近似,精选阶段等价于一次小规模的真实模型评估,因此能保证局部最优性。AutoDAN 同时在此阶段引入随机采样机制,以增加生成结果的多样性与鲁棒性。
4. 收敛判定与迭代稳定性
外层循环监控每个位置的 top-1 候选 token。若连续两轮的最优候选相同,即视为该位置已收敛并固定。该设计保证了生成过程的单调收敛性:
- 每轮都会保留当前 token 以防状态丢失;
- 精选阶段的打分函数单调不降;
- 候选空间有限,因此在有限步内必然达到稳定状态。
实验结果表明,实际收敛速度远快于理论上限。
阅读总结
优点: 1. 从零生成,无需人工提示模板; 2. 生成文本自然(低 PPL),能更好绕过简单检测;
缺点: 1. 依赖白盒梯度;在纯黑盒场景需借助代理或估计技巧; 2. 计算开销比较大;