Mesoscopic Insights: Orchestrating Multi-scale & Hybrid Architecture for Image Manipulation Localization
英文题目:《Mesoscopic Insights: Orchestrating Multi-scale & Hybrid Architecture for Image Manipulation Localization》
中文题目:《介观视角:协调多尺度和混合架构以实现图像操控定位》
论文作者:Xuekang Zhu, Xiaochen Ma, Lei Su1, Zhuohang Jiang,Bo Du, Xiwen Wang, Zeyu Lei, Wentao Feng, Chi-Man Pun, Jizhe Zhou
发布于:AAAI
发布时间:2025-04-11
级别:CCF-A
论文链接:https://doi.org/10.1609/aaai.v39i10.33198
论文代码:https://github.com/scu-zjz/Mesorch
摘要
介观层次在宏观世界和微观世界之间充当了桥梁,解决了两者忽略的鸿沟。图像操纵定位( Image Manipulation Localization,IML )是一种从虚假图像中寻找真相的关键技术,长期以来依赖于低级(微观)痕迹。然而,在实际应用中,大多数篡改旨在通过改变图像语义来欺骗观众。因此,操纵通常发生在物体层面(宏观层面),与微观痕迹同等重要。因此,将这两个层次整合到介观层次为IML研究提供了新的视角。 受此启发,本文探索如何同时为IML构建微观和宏观信息的介观表示,并引入Mesorch架构对两者进行编排。具体来说,该架构i )将Transformers和CNNs并行结合,Transformers提取宏观信息,CNNs捕获微观细节,ii )跨不同尺度探索,无缝评估微观和宏观信息。此外,基于Mesorch架构,本文介绍了两个旨在通过介观表示解决IML任务的基线模型。在4个数据集上的大量实验表明,我们的模型在性能、计算复杂度和鲁棒性方面都超过了当前的先进水平。
本文聚焦的问题
在图像篡改定位(IML)中:
- 传统方法只在微观层面看噪声、边缘、高频纹理等“篡改痕迹”;
- 但真实篡改往往是为了改变宏观语义 / 物体级内容(比如把人、车、重要物体抠掉或粘贴),仅看微观痕迹或仅看宏观语义都不够。
因此文章要解决的核心问题是:
怎么把微观的篡改痕迹和宏观的对象语义统一到一个“介观表征”里,并设计一个合适的网络结构,在这个介观层面上更精准、更鲁棒地做篡改区域定位。
本文提出的方法
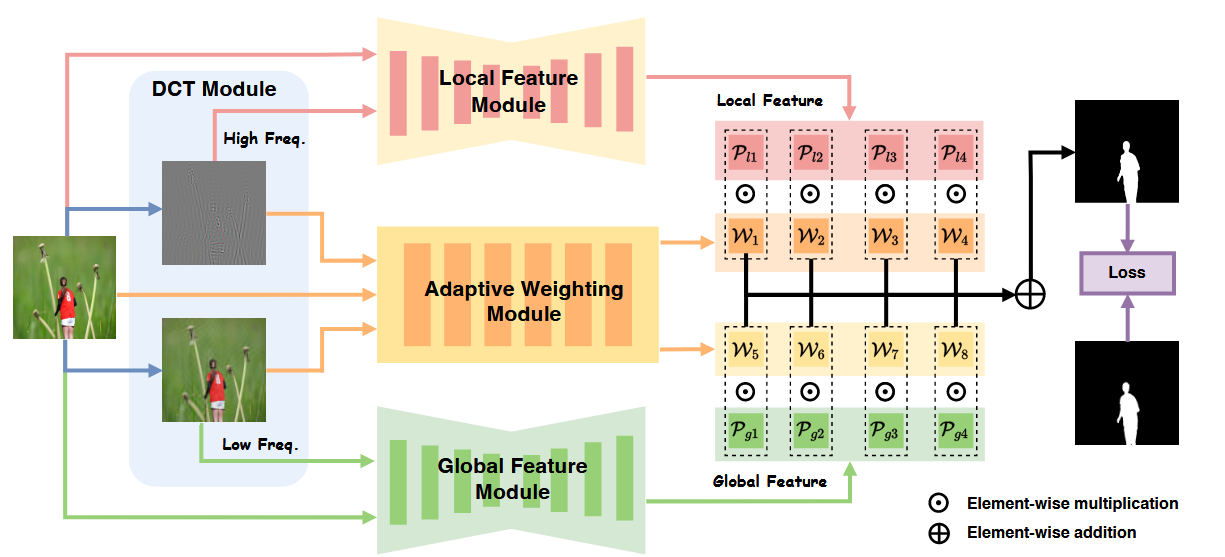
Mesorch框架的核心思想是并行处理,协同分析图像的微观与宏观信息。首先,输入图像通过离散余弦变换(DCT)被分解为高频和低频分量,并与原图融合,形成高频增强图和低频增强图。高频图被送入专用于捕捉局部细节的CNN模块(Local Feature Module),而低频图则被送入善于理解全局语义的Transformer模块(Global Feature Module)。两个模块并行地在四个不同尺度上提取特征。随后,解码器将这些多尺度特征图生成初步的篡改预测。最后,一个自适应加权模块动态地融合这些来自不同层次、不同来源的预测结果,生成最终的定位掩码。
阅读总结
优点
- 模拟人类视觉系统: 通过并行处理微观痕迹(CNN)和宏观语义(Transformer),模拟了人类专家在鉴定伪造图像时既关注像素级异常又理解场景逻辑的分析过程。
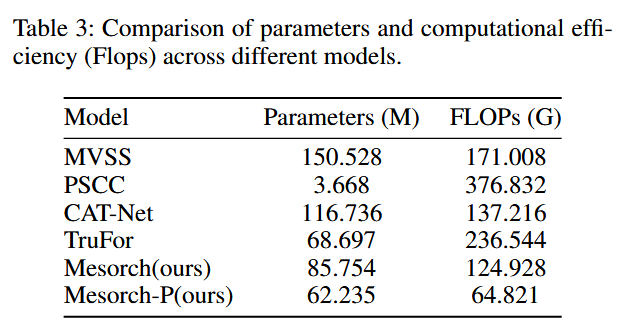
- 大幅降低计算成本: 通过自适应剪枝机制,模型能够去除冗余的计算分支,在几乎不损失性能的情况下,显著降低了FLOPs和参数量(如表3所示,Mesorch-P模型的FLOPs远低于其他SOTA模型)。
缺点
- 实验主要在几个人工构造的经典篡改数据集上做,离现在社交平台、多次压缩、AIGC 编辑那种复杂环境还有差距;
- 现在的“介观表征”主要体现在网络结构上:用 CNN 抓细节、用 Transformer 抓整体,再做多尺度融合,但训练时仍然只用普通分割损失,并没有专门要求不同尺度、不同分支的预测在语义上保持一致,也没有强调边界的精确性。可以在现有损失基础上,增加一个让各个尺度预测彼此相互贴近的“一致性约束”,再加一个鼓励轮廓清晰的边缘损失,让模型在学习过程中被明确要求:既要看清物体整体,又要画准细节边界。