Salience-Aware Face Presentation Attack Detection via Deep Reinforcement Learning
英文题目:《Salience-Aware Face Presentation Attack Detection via Deep Reinforcement Learning》
中文题目:《基于显著性感知的面部伪装攻击检测——深度强化学习》
论文作者:Bingyao Yu; Jiwen Lu; Xiu Li; Jie Zhou
发布于:TIFS
发布时间:2021-12-14
级别:CCF-A
论文链接:10.1109/TIFS.2021.3135748
论文代码:暂无
摘要
在本文中,我们提出了一种显著性感知面部伪装攻击 检测(SAFPAD)方法,该方法利用深度强化学习来挖掘面部 图像中的显著局部区域信息。大多数现有的深度面部伪装攻击检 测方法从整个图像或几个固定区域提取特征。然而,由于光照和 伪装攻击工具的变化,具有判别性的信息在图像中分布不均,因 此平等对待所有区域无法突出对更准确和鲁棒的面部伪装攻击检 测具有重要意义的判别性信息。为此,我们提出使用深度强化学 习识别具有判别性的显著区域,并专注于这些区域以减轻面部图 像中冗余信息的不利影响。我们融合高级特征和局部特征,指导 策略网络挖掘判别性块,并协助分类网络预测更准确的结果。我 们使用深度强化学习联合训练SAFPAD模型以生成显著位置。 在五个公共数据集上的大量实验表明,由于显著局部信息的集中 使用,我们的方法取得了非常有竞争力的性能。索引词—面部伪 装攻击检测,深度强化学习,多尺度特征融合。
本文聚焦的问题
**场景:**单张 RGB 图像的人脸呈现攻击检测(Face PAD),也就是只用一帧图像判断是真人还是打印/重放/面具攻击。
痛点:现有很多基于纹理/深度学习的方法,要么直接吃整张图,要么在几个 固定区域(如全脸网格)上提特征,没有显式区分出“特别关键的局部线索”。
实际上,由于光照和攻击道具变化,真正有判别力的信息在图像中分布不均匀,比如:打印照片边缘、屏幕莫尔纹、反光伪影、人脸与背景边界等。平等对待所有区域,会被大量冗余信息稀释。
核心问题:如何自动发现并聚焦于这些“显著局部块”, 而不是一视同仁地处理整张脸?
本文提出的方法
本文提出了一种显著性感知的人脸攻击检测方法:先用一个网络对整张人脸提取全局特征(并通过深度图回归获得更稳定的3D结构信息),再由一个带记忆的“显著性代理”在图像上逐步选择少量局部补丁作为关键观察区域;每一步将当前补丁的局部特征与全局特征融合后输入循环网络更新状态,并最终基于多步累积的融合特征判断真人或攻击。这个“去哪儿看”的选择过程通过深度强化学习来训练,奖励由最终分类是否正确以及所选位置是否足够分散共同决定,从而引导模型自动学会关注那些最有助于区分真人与攻击的显著区域。
他们把“选显著块的位置”建模成一个马尔可夫决策过程(MDP),包含状态、动作和基于 REINFORCE 的学习过程:
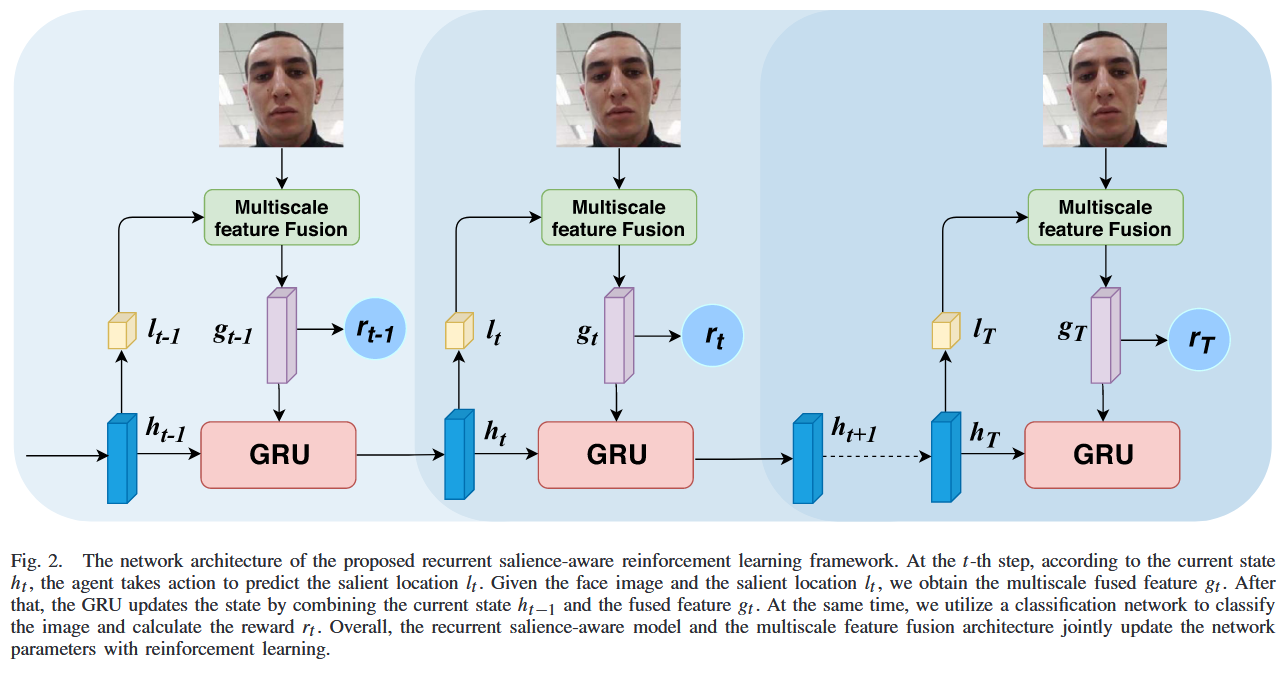
(1) 状态
在第步的状态由两部分特征构成:
-
全局高层特征
用一个“高层特征编码网络”从整张人脸图像提取,例如通过 CNN 并结合深度图回归作为辅助监督,得到整体的结构与上下文信息。
-
当前显著块的局部特征
在位置 上裁一个的小块(如),通过局部 CNN 提取该补丁的局部纹理/边缘等特征。
将二者拼接成融合特征:
再用GRU更新隐藏状态:
也就是说,状态 里既有全局上下文,又通过隐藏状态记住了前面已经看过哪些区域、看到了什么信息。
(2) 动作:选下一个显著位置
策略网络以当前隐藏状态为输入,输出一个在特征图上的位置概率分布:
具体做法是:
- 从该概率图中选出概率最高的位置,作为高斯分布的均值;
- 以固定方差在这一分布上进行采样,并将采样结果归一化映射回原图坐标;
- 得到下一步要裁剪的补丁中心位置 。
这相当于一个“看图放大镜”:每一步根据之前“看到的信息”(状态),决定下一块要放大查看的显著区域。
(3)奖励设计
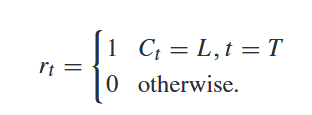
(4) 学习:REINFORCE + 监督学习联合训练
在更新策略网络时,他们使用 REINFORCE 策略梯度:
其中:
- :策略网络,对位置给出概率分布;
- :第 (m) 个样本的总奖励(由分类结果与位置多样性等共同构成);
- :由值网络估计的基线,用于降低梯度方差。
同时,他们还通过普通的反向传播训练两个监督分支:
- 深度图回归损失:逼近真实或伪造的深度图,用来增强全局结构表征;
- 分类交叉熵损失:将融合特征输入分类头,做活体/攻击二分类。
最终效果可以概括为:
- 策略网络通过强化学习学会“去哪看”(选择哪些显著位置裁补丁);
- 特征提取和分类网络通过监督学习学会“怎么看 / 怎么判”(从这些区域和全局信息中提取判别特征);
两者共享特征并联合优化,从而实现一个既会找重点区域、又会做出正确判断的显著性引导人脸攻击检测模型。
阅读总结
本篇论文的收获
把“看哪里”显式建模成强化学习问题,之前的 PAD 工作多数是:直接全图卷积,或者在预定义网格/固定部位上提特征。本文通过循环 agent 顺序选 patch,相当于实现了一个硬注意力(hard attention)机制,而且是“看-想-再看”的多步过程,很适合作为后续 RL + 视觉任务的参考范例。
**多尺度特征融合 + 深度监督,有助于泛化:**高层特征编码网络在深度图回归的辅助监督下学习到比较稳定的 3D 结构信息,再和显著 patch 的纹理特征融合。消融实验表明,去掉高层特征编码或多尺度融合,性能明显下降,这说明“全局上下文指挥局部搜索”是本方法的关键。
本篇论文的缺陷
**奖励设计偏简单,信号非常稀疏:**分类奖励只在最后一步给 0/1,中间所有动作都拿不到即时反馈,这让策略很难判断“哪几步选的位置真正起了关键作用”,训练方差较大,探索难度巨大、样本效率极低。