Towards Universal AI-Generated Image Detection by Variational Information Bottleneck Network
英文题目:《Towards Universal AI-Generated Image Detection by Variational Information Bottleneck Network》
中文题目:《基于变分信息瓶颈网络的通用AI生成图像检测》
论文作者:Haifeng Zhang; Qinghui He; Xiuli Bi; Weisheng Li; Bo Liu; Bin Xiao
发布于:CVPR
发布时间:2025-06-10
级别:CCF-A
论文链接:10.1109/CVPR52734.2025.02219
论文代码:https://github.com/oceanzhf/VIBAIGCDetect
摘要
生成模型的快速发展为生成图像质量显著提升提供了可能。与此同时,它也挑战了信息的真实性和可信度。基于大规模预训练多模态模型的当前生成图像检测方法已取得令人瞩目的成果。尽管这些模型提供 了丰富的特征,但与认证任务相关的特征往往被淹没。 因此,那些与认证任务无关的特征会导致模型学习表 面化的偏差,从而损害其在不同生成模型(例如 GANs和扩散模型)上的泛化性能。为此,我们提出了 VIB-Net,该模型利用变分信息瓶颈来强制学习与认证 任务相关的特征。我们在由17种不同生成模型生成的 样本上测试并分析了所提出的方法和现有方法。与 SOTA方法相比,VIB-Net在mAP上提高了5.55%,在 准确率上提升了9.33%。值得注意的是,在针对来自 不同系列的未见过的生成模型的泛化测试中, VIB-Net在mAP上比SOTA方法提高了12.48%,在准 确率上提高了23.59%。代码可在 https://github.com/oceanzhf/VIBAIGCDetect获取。
本文聚焦的问题
现有的问题:大规模预训练多模态模型提取的通用特征比预训练视觉模型提取的特征更有利于真实‑伪造图像分类任务。然而对规模与训练多模态模型提取通用特征往往包含一些与任务无关的特征,这些与任务无关的特征会影响真实和伪造图像的分类。
因此本文采用变分瓶颈网络,对大规模预训练多模态模型提取到的通用特征进行再建模:通过在中间表示处引入带噪声的“瓶颈层”,约束特征中能够通过的信息量,使网络在保证认证性能的前提下主动舍弃与真实-伪造判别无关的冗余模式,仅保留与任务高度相关的判别性信息。
本文提出的方法
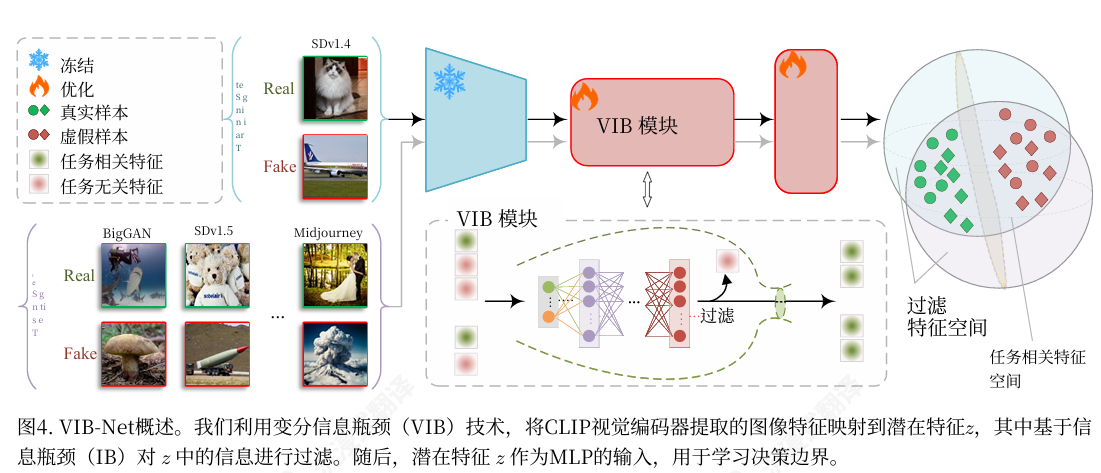
本文的方法
在普通神经网络中间加一个“带噪声的信息瓶颈层”, 通过限制中间表示能从输入中“带出多少信息”,让模型只保留对任务有用的关键信息,丢掉多余细节和噪声。
具体做法
特征中间表示不再是确定向量,而是一个“有均值和不确定性”的随机表示,再通过一个信息约束(让它不要偏离一个简单先验分布太多),来控制“通道带宽”,防止模型记太多与任务无关的内容,同时仍然用正常的任务损失(分类误差)保证预测效果。
方法流程
先把输入数据送入基础网络提取特征,再经过一个“变分信息瓶颈层”把特征变成一个带不确定性的压缩表示(从中采样得到中间表示),然后用这个中间表示完成下游任务预测,同时在训练时一边最小化预测误差,一边约束这个中间表示不要带太多来自输入的冗余信息,从而学到既紧凑又对任务有用的表示。
阅读总结
本篇论文的收获
把“好特征”讲清楚了,不是“特征维度多就好”,而是:能够预测任务结果,但又不携带太多和任务无关细节的特征,才是真正好的表示。
让抽象的“信息瓶颈”变得可实现,原始的信息瓶颈更多停留在理论层面,很难直接在神经网络里用。而这篇文章原始的信息瓶颈更多停留在理论层面,很难直接在神经网络里用。
本篇论文的缺陷
在超大规模模型/数据上的验证相对有限,实验主要是中小数据集(MNIST、CIFAR 等)。对于特别大规模的真实任务(如大规模文本、多模态数据),是否始终明显优于简单的正则化方法,还没完全讲清楚。
理论很美,但距离真实互信息还有差距,由于互信息太难精确计算,论文用的是各种近似和上界,意味着我们优化的东西和“理想中的信息瓶颈目标”并不完全一样,存在一定理论上的 gap。