BERT-ATTACK: Adversarial Attack Against BERT Using BERT
英文题目:《BERT-ATTACK: Adversarial Attack Against BERT Using BERT》
中文题目:《BERT-ATTACK:使用 BERT 对 BERT 的对抗攻击》
论文作者: Linyang Li, Ruotian Ma, Qipeng Guo, Xiangyang Xue, Xipeng Qiu
发布于: EMNLP2020
发布时间:2020-04-21
级别:CCF-B
摘要
对于离散数据(如文本)的对抗攻击已被证明比连续数据(如图像)更具挑战性,因为基于梯度的方法难以生成对抗样本。当前成功的文本攻击方法通常采用字符或单词级别的启发式替换策略,但在大量的可能替换组合空间中找到最佳解决方案,同时保持语义一致性和语言流畅性仍然具有挑战性。在本文中,我们提出 BERT-Attack,这是一种高质量且有效的方法,可以使用以 BERT 为例的预训练掩码语言模型来生成对抗样本。我们将 BERT 应用于其微调模型和下游任务中的其他深度神经模型,以便我们能够成功地误导目标模型进行错误的预测。我们的方法在成功率和扰动百分比方面均优于最先进的攻击策略,同时生成的对抗样本流畅且语义保留完整。此外,计算成本较低,因此可以进行大规模生成。代码可在 https://github.com/LinyangLee/BERT-Attack 获取。
本文聚焦的问题
本文的核心目标是:设计一种基于预训练掩码语言模型(BERT)的对抗攻击方法,在 “高攻击成功率”“低扰动率(人类不可感知)”“高语义流畅性”“低计算成本” 之间实现平衡,同时能有效攻击微调 BERT 及其他主流 NLP 模型(如 LSTM、ESIM、BERT-Large),为验证模型鲁棒性提供可靠工具。
本文提出的方法
BERT是一个在极其大规模的无监督数据上预训练的掩码(在输入文本中随机地遮盖或替换掉一些词语,然后让模型去预测这些被遮盖的词语是什么)语言模型,能够理解和生成高质量语言的智能模型,且它是一种预训练语言模型。
文章受到将 BERT 用于对抗 BERT 这一有趣想法的启发,提出了 BERT-Attack,使用原始的 BERT 模型来生成对抗样本,以欺骗微调后的 BERT 模型。其流程图如下所示:
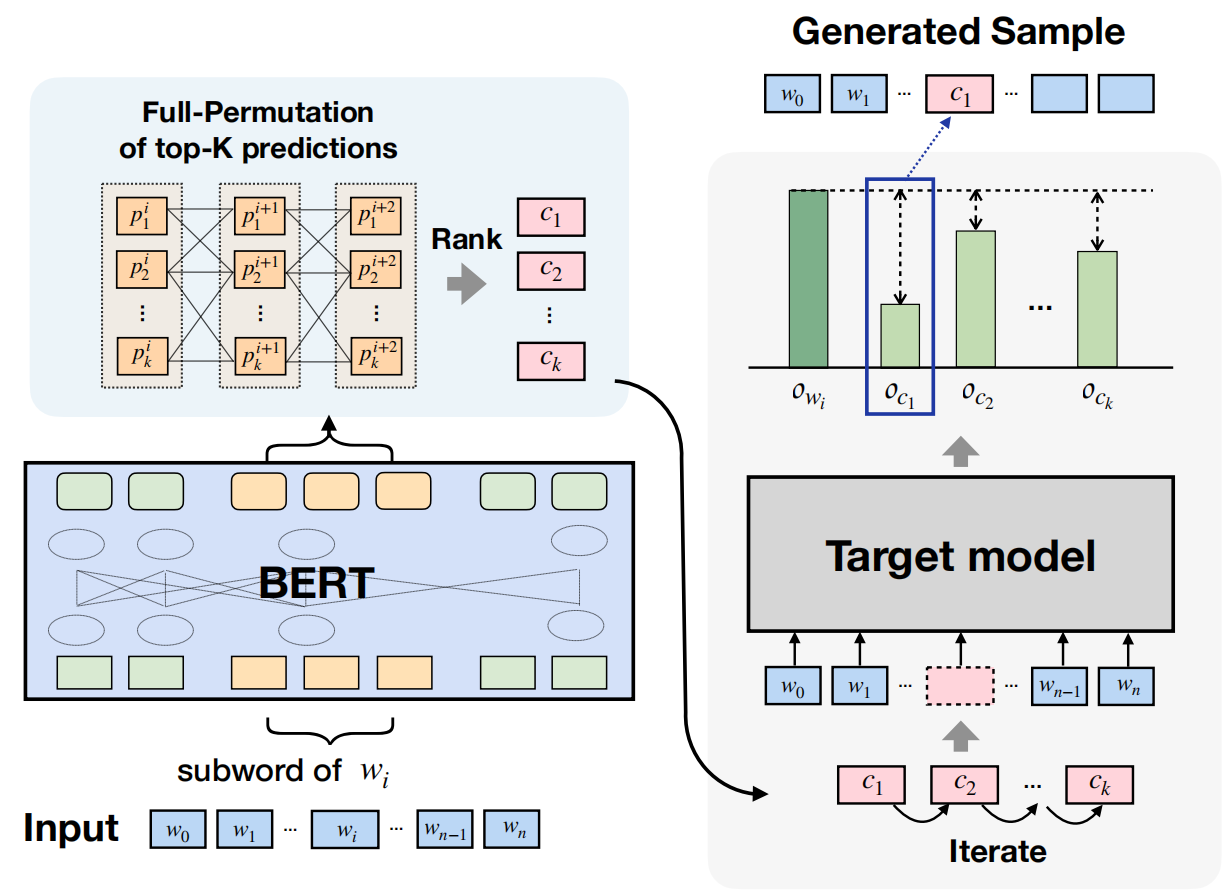
大致过程是将原句子分词然后输入进入BERT,BERT会对每一个分词给出top-k个可替换的分词。如果一个分词就表示一个词,那么这top-k个分词就是他的备选;如果多个分词表示一个词,比如说三个分词表示一个词,那么就有k * k * k,然后会根据困惑度就行打分,选前k个。那么现在对于每一个单词就都有top-k个可替换词。接下来我们对在原句子中最容易影响判断的词就行替换(如何获得最敏感下面算法有具体介绍),最后就是依次对每个敏感词进行替换,每次都先对一个敏感词进行k轮替换,如果直接让模型判断成功就结束,否则依据logit,选择最优的(让模型对正确分类概率最低的),然后换下一个敏感词进行k轮替换。
该过程的具体算法如下:

- 识别脆弱词(WORD IMPORTANCE RANKING)
输入准备: 算法接收一个分词后的输入句子 S 和该句子的正确标签 Y。
计算重要性得分: 对于句子 S 中的每一个词 w_i,算法会计算其重要性得分。Iwi = Oy(S)- Oy(S \ Wi)。
构建脆弱词列表: 计算出所有词的重要性得分后,算法会根据 Iwi 的降序排列所有词,并选择最重要的前 K 个词(或某个百分比的词。这些词是攻击的首要目标。
- 使用 BERT 进行词替换(REPLACEMENT USING BERT)
子词(sub-word)处理: 首先,输入句子 S 会被 BERT 的分词器转换为子词序列 H。
生成候选词: 使用 BERT 模型,为序列 H 中的每个位置(即每个子词)生成其最可能的 K 个预测候选词,形成一个预测矩阵 P。这个过程只需进行一次 BERT 推理。
迭代替换脆弱词: 算法遍历脆弱词列表 L 中的每个词 w_j,尝试替换它们以生成对抗样本。
对于完整的词(whole word): 如果 w_j 是一个完整的词(没有被 BERT 分成多个子词),算法会从 BERT 为该词位置预测的候选词中,通过 Filter(Pj) 函数筛选出合适的替换候选集 C。这个筛选通常会移除停用词、反义词等不合适的词。
对于子词(sub-words): 如果 w_j 被 BERT 分解成多个子词,算法会利用所有这些子词位置的预测候选,通过 PPL (Perplexity) 排名和过滤来构建替换候选集 C。这涉及到组合不同子词的预测,然后评估组合后的困惑度来选择最佳组合。
寻找对抗样本: 对于每一个选定的脆弱词 w_j 及其生成的候选替换词集 C:
算法会遍历 C 中的每一个候选词 c_k,将其替换到原始句子 S 中的 w_j 位置,得到一个尝试样本S’。
然后,将 S’ 输入目标模型进行预测:
成功攻击: 如果目标模型对 S’ 的预测结果不再是原始的正确标签 Y,则表示攻击成功,当前的 S’ 就是一个对抗样本 Sadv,算法立即返回这个对抗样本。
未成功但更接近: 如果当前候选词 c_k 未能使模型预测错误,但它使得模型对原始正确标签的预测 logit 值比之前尝试的任何候选词(或初始值)更低,那么就更新 Sadv 为当前的 S’。这意味着虽然还没有完全欺骗模型,但这个替换让模型“更不确定”原始标签了,保留它作为最佳的局部扰动。
无对抗样本: 如果遍历完所有脆弱词和它们的候选替换词后,仍未能找到一个能够成功欺骗模型的样本,算法将返回 None。
阅读总结
优点:
1、计算效率更高:低查询 + 少冗余推理,解决了传统方法(如 GA、TextFooler)“试错式生成” 的低效问题,计算成本大幅降低。
2、样本质量更高:语义一致 + 语法流畅,生成的对抗样本在语义和语法上与原始样本高度接近,未出现明显失真或生硬表达。
缺点:
1、短序列攻击效果有限,依赖上下文的替换策略在极短序列(如短假设句、短语级文本)中效果不佳,易生成不自然的扰动。
2、子词处理复杂度较高,针对 BPE 分词的子词替换需计算组合困惑度(PPL),虽有效但增加了部分实现复杂度,且对罕见词的子词组合筛选可能存在遗漏。
未来可以将 BERT-ATTACK 与词嵌入替换、短语级扰动结合,针对短文本补充上下文信息,避免替换后句子生硬。