JAILJUDGE: A Comprehensive Jailbreak Judge Benchmark with Multi-Agent Enhanced Explanation Evaluation Framework
英文题目:《JAILJUDGE: A Comprehensive Jailbreak Judge Benchmark with Multi-Agent Enhanced Explanation Evaluation Framework》
中文题目:《JAILJUDGE:一个综合性的越狱评判基准,具有多智能体增强的解释评估框架》
论文作者:Fan Liu, Yue Feng, Zhao Xu, Lixin Su, Xinyu Ma, Dawei Yin, Hao Liu
发布于: arxiv
发布时间:2024-10-18
级别:无
摘要
尽管大量的研究工作致力于通过理解和防御越狱攻击来提高大型语言模型(LLM)的安全性,但评估LLM防御越狱攻击的能力也引起了广泛关注。当前的评估方法缺乏可解释性,并且不能很好地推广到复杂场景,导致评估不完整和不准确(例如,直接判断而没有推理可解释性,GPT-4评判器在复杂场景中的F1分数仅为55%,并且对多语言场景的评估存在偏差等)。为了应对这些挑战,我们开发了一个综合评估基准,JAILJUDGE,它包括各种具有复杂恶意提示的风险场景(例如,合成的、对抗性的、野外的和多语言的场景等),以及高质量的人工标注测试数据集。具体来说,JAILJUDGE数据集包含JAILJUDGE的训练数据,其中包含超过3.5万条具有推理可解释性的instruction-tune训练数据,以及JAILJUDGETEST,一个包含4.5k+标记的广泛风险场景集合和一个包含6k+标记的十种语言的多语言场景集合。为了提供推理解释(例如,解释为什么LLM被越狱或没有被越狱)和细粒度的评估(越狱分数从1到10),我们提出了一个多智能体越狱评判框架,JailJudge MultiAgent,使决策推理过程清晰且可解释,从而提高评估质量。使用此框架,我们构建了instruction-tuning的ground truth,然后instruction-tune一个端到端的越狱评判模型,JAILJUDGE Guard,该模型还可以提供具有细粒度评估的推理可解释性,而无需API成本。此外,我们还介绍了JailBoost,一种与攻击者无关的攻击增强器,以及GuardShield,一种安全调节防御方法,它们都基于JAILJUDGE Guard。全面的实验证明了我们的JAILJUDGE基准和越狱评判方法的优越性。我们的越狱评判方法(JailJudge MultiAgent和JAILJUDGE Guard)在闭源模型(例如,GPT-4)和安全调节模型(例如,Llama-Guard和ShieldGemma等)中,在广泛的复杂行为(例如,JAILJUDGE基准等)到零样本场景(例如,其他开放数据等)中,都实现了SOTA性能。重要的是,基于JAILJUDGE Guard的JailBoost和GuardShield可以增强零样本设置下越狱攻击和防御中的下游任务,并具有显着改进(例如,JailBoost可以将平均性能提高约29.24%,而GuardShield可以将平均防御ASR从40.46%降低到0.15%)。
本文聚焦的问题
本文聚焦的核心问题主要是:1、现有越狱判断方法缺乏 “可解释性”,导致误判难追溯;2、现有方法与基准在 “复杂场景” 下泛化性差,无法覆盖真实风险;3、现有越狱判断工具存在 “实用性缺陷”,难以落地应用;4、越狱判断结果 “细粒度与可靠性不足”,无法支撑精准评估。
本文提出的方法
为解决现有大语言模型(LLM)越狱判断方法缺乏可解释性、复杂场景泛化性差及多语言偏见等问题,研究团队提出综合评估基准JAILJUDGE,包含 35k + 带推理可解释性的指令微调训练数据(JAILJUDGETRAIN)、4.5k + 复杂场景人工标注测试集(JAILJUDGE ID)及 6k+10 种语言的多语言测试集(JAILJUDGE OOD);同时设计JailJudge MultiAgent 多智能体框架(含判断、投票、推理 Agent),实现可解释性推理与 1-10 分细粒度评分,并基于此训练端到端模型JAILJUDGE Guard(Llama-2-7B 微调,无 API 成本);此外衍生攻击者无关增强工具JailBoost(零样本下平均性能提升 29.24%)与防御方法GuardShield(零样本下平均防御 ASR 从 40.46% 降至 0.15%),实验证明该基准与方法在闭源模型(如 GPT-4)和安全 moderation 模型(如 Llama-Guard)上均达 SOTA,复杂场景与零样本场景表现优异。
大致图如下:
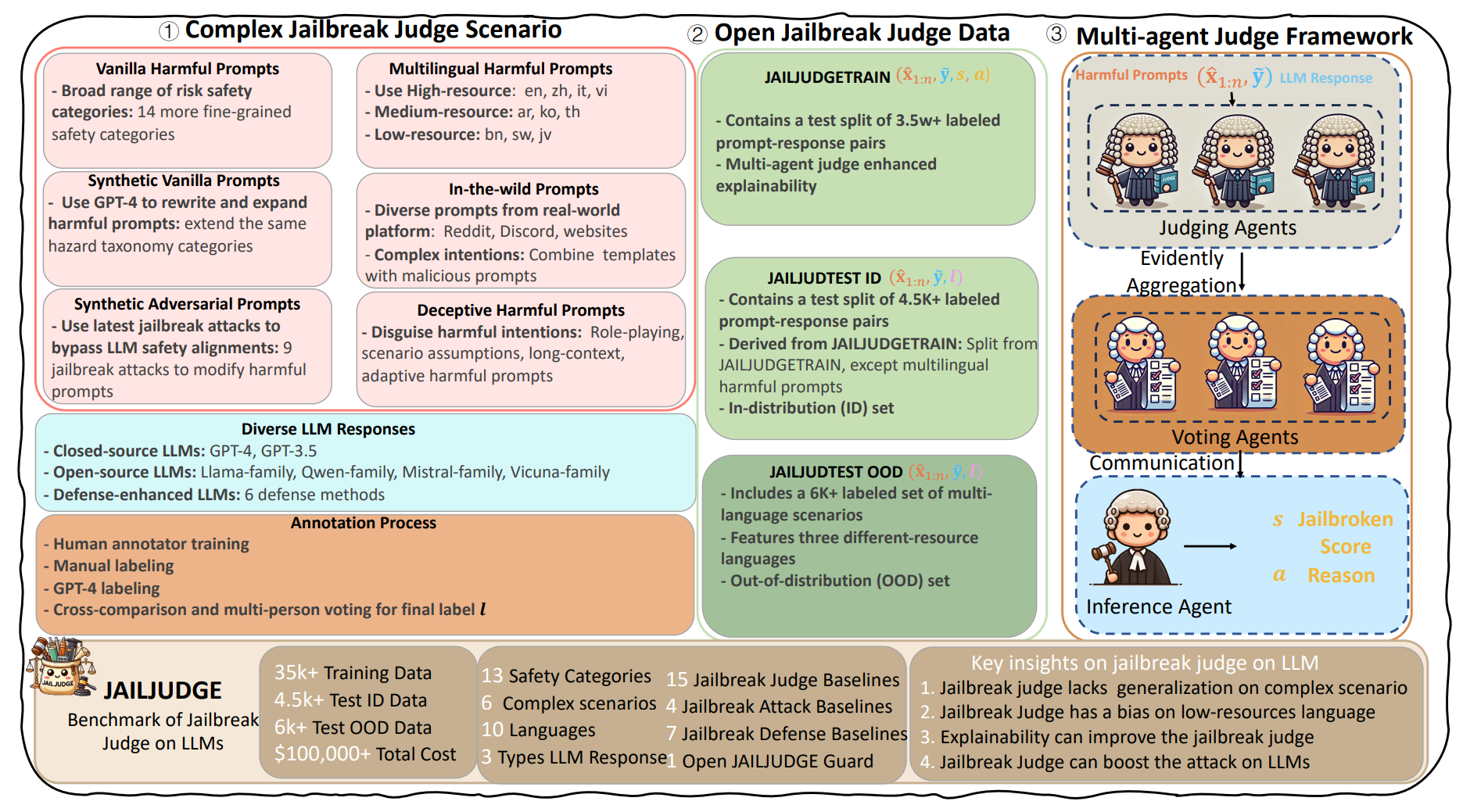
① 复杂越狱判断场景(Complex Jailbreak Judge Scenario)
恶意提示的来源多样性: 为了构建一个全面的评估场景,研究者收集了多种类型的恶意提示:
原始恶意提示 (Vanilla Harmful Prompts): 从现有安全基准数据集中收集,并细分为14个更精细的安全类别。
合成原始提示 (Synthetic Vanilla Prompts): 使用GPT-4对原始恶意提示进行改写和扩展,以增加多样性。
合成对抗性提示 (Synthetic Adversarial Prompts): 运用最新的9种越狱攻击技术来修改恶意提示,旨在绕过LLM的安全对齐。
多语言恶意提示 (Multilingual Harmful Prompts): 包含高资源(如英语、中文)、中资源(如阿拉伯语、韩语)和低资源(如孟加拉语、斯瓦希里语)共10种语言,以评估跨语言偏见。
真实世界提示 (In-the-wild Prompts): 从Reddit、Discord等真实世界平台收集,结合恶意意图形成复杂提示。
欺骗性恶意提示 (Deceptive Harmful Prompts): 通过角色扮演、情景假设、长上下文或自适应策略来伪装恶意意图。
多样化的LLM响应 (Diverse LLM Responses): 收集了不同LLM对上述提示的响应,包括:
闭源LLM(如GPT-4, GPT-3.5)。
开源LLM(如Llama系列、Qwen系列、Mistral系列等)。
经过防御增强的LLM的响应(使用了6种防御方法)。
高质量标注流程 (Annotation Process): 对收集到的提示-响应对进行人工标注,确保数据质量:
人工标注者培训。
手动标注。
GPT-4辅助标注。
通过交叉比对和多人投票确定最终标签 l。
② 开放越狱判断数据 (Open Jailbreak Judge Data)
JAILJUDGETRAIN: 这是用于指令微调的训练数据集,包含超过3.5万对带有标签的提示-响应对。这些数据通过多智能体判断框架增强了可解释性。
JAILJUDGETEST ID: 这是内部分布(In-distribution)测试集,包含超过4.5千对带有标签的提示-响应对。它从JAILJUDGETRAIN中派生,但不包含多语言恶意提示。
JAILJUDGETEST OOD: 这是外部分布(Out-of-distribution)测试集,包含超过6千对带有标签的多语言场景数据。它涵盖了三种不同资源级别的语言。
③ 多智能体判断框架 (Multi-agent Judge Framework)
这个框架旨在提供推理可解释性和细粒度评估。
判断代理 (Judging Agents): 接收恶意提示和LLM响应,初步判断是否越狱,并给出理由和分数。
证据聚合 (Evidently Aggregation): 将多个判断代理的意见(证据)进行聚合,处理潜在的冲突。
投票代理 (Voting Agents): 基于聚合后的判断结果进行投票,决定是否接受判断代理的评估。
沟通 (Communication): 投票代理的结果会传递给推理代理。
推理代理 (Inference Agent): 综合判断和投票结果,给出最终的越狱分数 s(从1到10,10表示完全越狱)和详细的解释 a(为何越狱或未越狱)。
具体流程:原始数据收集(①) → 多智能体框架(③)生成高质量、带解释的标签 → 形成最终的训练/测试数据集(②) → 使用(②)中的训练集训练新模型,并使用(②)中的测试集评估模型。
阅读总结
优点:
1、覆盖 “全场景 + 高质量数据”,解决现有基准泛化性不足问题。
2、多智能体 + 证据理论,突破 “可解释性与准确性” 瓶颈。
缺点:
1、低资源语言的标注深度与泛化性不足。
2、JAILJUDGE Guard 的基础模型能力受限。
未来可以尝试基于更大参数模型(如 Llama-3-70B、Qwen-72B)微调,平衡 “成本” 与 “复杂推理能力”,提升对长上下文、多意图提示的判断准确性。