Pixel level deep reinforcement learning for accurate and robust medical image segmentation
英文题目:《Pixel level deep reinforcement learning for accurate and robust medical image segmentation》
中文题目:《像素级深度强化学习用于精确和鲁棒的医学图像分割》
论文作者:Yunxin Liu, Di Yuan, Zhenghua Xu, Yuefu Zhan, Hongwei Zhang, Jun Lu& Thomas Lukasiewicz
发布于:Scientific Reports
发布时间:2025-03-10
级别:SCI升级版 综合性期刊3区
论文链接:https://www.nature.com/articles/s41598-025-92117-2
论文代码:暂无
摘要
现有的深度学习方法在医学图像分割方面取得了显著成功。然而,这种成功在很大程度上依赖于堆叠先进的模块和架构,从而形成了一种路径依赖。这种路径依赖是不可持续的,因为它导致模型参数越来越大,部署成本也越来越高。为了打破这种路径依赖,我们引入深度强化学习来提高分割性能。然而,当前的深度强化学习方法面临着训练成本高、独立迭代过程以及分割掩码不确定性高等挑战。因此,我们提出了一种基于像素级的深度强化学习模型,具有逐像素掩码生成(PixelDRL-MG)功能,用于更精确和鲁棒的医学图像分割。PixelDRL-MG采用动态迭代更新策略,可以直接分割感兴趣区域,无需用户交互或粗略分割掩码。我们提出了一种基于像素级的异步优势演员-评论家(PA3C)策略,将每个像素视为一个智能体,其状态(前景或背景)通过直接动作进行迭代更新。我们在两个常用的医学图像分割数据集上进行的实验表明,PixelDRL-MG比最先进的分割基线(尤其是在边界处)实现了更优越的分割性能,同时使用的模型参数显著更少。我们还进行了详细的消融研究,以增强理解并促进实际应用。此外,PixelDRL-MG在低资源设置(即50次或100次)中表现良好,使其成为现实场景的理想选择。
本文聚焦的问题
深度学习分割的“路径依赖”问题
- 目前医学图像分割几乎都沿着“U-Net → 不断加模块/加骨干”的路线在演进,比如 Attention U-Net、U-Net++、Swin-UNet、TransUNet 等。
- 提升效果往往依赖堆叠更复杂的注意力模块、Transformer 模块、密集跳连等,导致参数量越来越大、部署成本越来越高,却依然难以从根本上解决边界模糊的问题。
现有基于深度强化学习分割方法的三大缺陷
文章系统总结了已有 DRL 分割方法的几个痛点:
训练成本高:需要先预训练一个分割网络生成粗分割,再用强化学习做迭代细化;交互式方法还需要专家在每个样本上反复标注“提示/交互”,人力成本极高。
迭代过程彼此独立:每一步只在当前概率图上局部调整,没有充分利用全局信息和邻域像素信息;步数多、过程长但缺乏“整体规划感”。
分割结果不确定性高:大多先输出概率图,再通过阈值二值化 → 引入量化误差和精度损失,尤其在边界处表现不稳定。
本文工作
与检测任务不同,医学图像分割通常目标位置并不难大致定位,难点在于像素级精确勾勒边界(器官轮廓、肿瘤边缘等)。因此作者思考:能否抛开“在 U-Net 上继续堆模块”的套路,转而用像素级的决策过程来模拟医生“从粗到细修改标注”的行为。
本文提出的方法
把每一个像素当作一个智能体(agent),用强化学习反复决策:这个像素是前景还是背景,直接生成二值掩膜,而不是先生成概率图再阈值化。
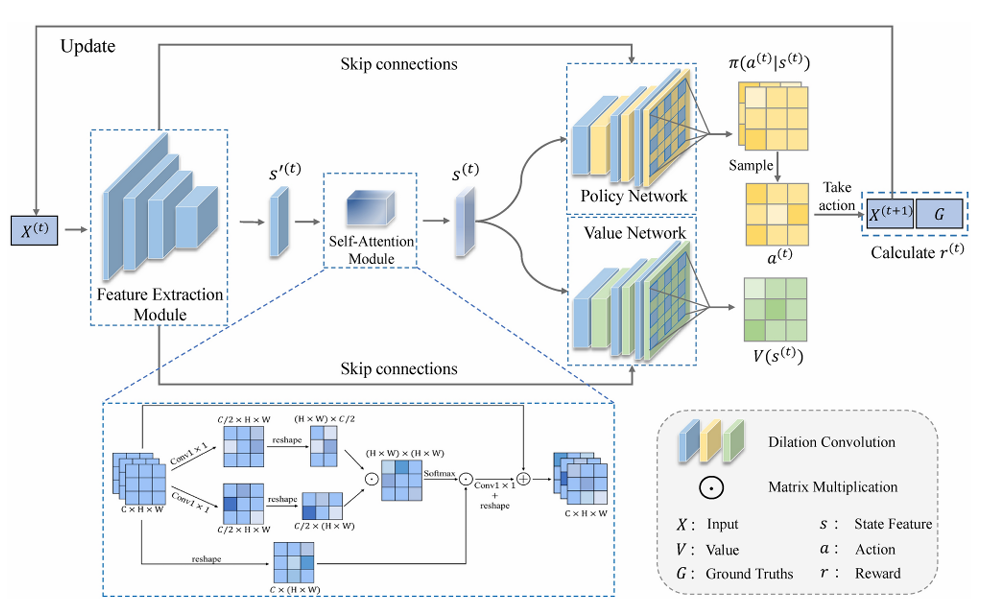
具体流程
输入当前图像X(t)(初始时就是原始图像),经过 VGG16 特征提取模块(通道减半 + 空洞卷积),得到多尺度特征s′(t)
进入 自注意力模块 SAM,获取全局上下文后得到s(t)。
s(t)被送入:
- 策略网络(policy network):输出每个像素在“动作集合”上的概率分布;
- 价值网络(value network):输出每个像素当前状态的价值 V(s(t))。 两个网络每一层都用 空洞卷积(DC) 扩大感受野、捕获邻域像素信息。
策略网络对每个像素采样动作:
- 动作 1:将该像素设为 0(背景)
- 动作 2:什么也不做(保留当前值,视作前景)
根据所有像素的动作更新图像X(t),并与真值掩膜 G计算奖励,进入下一步迭代,多次迭代后,输出图像逐渐逼近真实掩膜。
关键模块
PA3C
在经典 A3C 的基础上做了三点重要改造:
像素级 agent 设计
每个像素是一个 agent,状态就是当前像素值;
输出的价值图与输入同分辨率,每个像素一个价值;
策略网络输出 shape 为 (H, W, 2) 的动作概率图,两通道分别是 “设为 0” 与 “不变”。
邻域依赖的动态迭代策略
借助空洞卷积,某像素的下一状态不仅受自身动作影响,还受邻域 N(i)N(i)N(i) 中像素的价值影响;
在价值更新公式中引入权重wi − j,表示邻域像素对当前像素的影响程度,这些权重通过学习获得。
端到端像素决策,不再依赖阈值
传统做法:对概率图设阈值 → 二值掩膜;
文中做法:策略网络直接输出“0 或不变”的动作,掩膜在迭代过程中天然就是二值的,从根源上减少了阈值造成的量化误差。
自注意力模块(SAM)——提供全局信息
强化目标区域、抑制背景噪声,使每个像素的决策能看到更远的上下文。
空洞卷积(DC)——提供邻域信息
在 PA3C 的策略/价值网络中每层都使用空洞卷积,这样可以:
避免频繁下采样导致分辨率降低;
同时显著扩大感受野,使某像素的决策考虑到更大区域的邻域信息,而不仅是自己这一点。
阅读总结
创新点总结
- 把医学图像分割重新表述为“像素级决策问题”,而不是仅仅改进 U-Net 架构,将每个像素是一个 Agent,强化学习直接学“保留/置零”两类动作,输出的就是最终掩膜,不再依赖阈值。
- 在 A3C 框架上同时引入 全局自注意力(SAM)+ 空洞卷积邻域建模 + 特制奖励函数,完成从“游戏式 RL”到“像素级分割 RL” 的迁移。
不足
仍然依赖较“老”的 CNN 骨干(VGG16 + DC),虽然有利于控制参数和内存,但与最新 Vision Transformer 系列相比,特征表达上可能还有提升空间。
启发
分割不一定非要依赖更大的 U-Net 或更复杂的模块,完全可以把“每个像素属于哪个类别”当作一系列可学习的动作决策。