PixelRL Fully Convolutional Network with Reinforcement Learning for Image Processing
英文题目:《PixelRL Fully Convolutional Network with Reinforcement Learning for Image Processing》
中文题目:《PixelRL 全卷积网络结合强化学习用于图像处理》
论文作者:Ryosuke Furuta,Naoto Inoue,Toshihiko Yamasaki
发布于:TMM
发布时间:2019-07
级别:CCF-A
论文代码:rfuruta/pixelRL
摘要
本文探讨了一个新的问题设置:基于像素级奖励的强化学习(pixelRL)在图像处理中的应用。自从深度Q网络出现以来,深度强化学习(RL)取得了巨大的成功。然而,深度强化学习在图像处理中的应用仍然有限。因此,我们将深度强化学习扩展到pixelRL,以应用于各种图像处理场景。在pixelRL中,每个像素都有一个智能体,该智能体通过执行动作来改变像素值。我们还提出了一种有效的pixelRL学习方法,该方法不仅考虑自身像素的未来状态,还考虑相邻像素的未来状态,从而显著提高了性能。所提出的方法可以应用于一些需要像素级操作的图像处理任务,而深度强化学习此前从未应用于这些任务。此外,还可以可视化每次迭代中每个像素所执行的操作,这有助于我们理解为什么以及如何选择这些操作。我们还相信,我们的技术可以增强深度神经网络的可解释性和可理解性。此外,由于每个像素执行的操作都是可视化的,因此我们可以根据需要更改或修改这些操作。
我们将提出的方法应用于各种图像处理任务:图像去噪、图像复原、局部颜色增强和基于显著性的图像编辑。我们的实验结果表明,与基于监督学习的现有方法相比,我们提出的方法能够达到相当或更优的性能。 源代码可在 https://github.com/rfuruta/pixelRL 获取。
本文聚焦的问题
深度强化学习在低层图像处理中的局限 近年来深度强化学习(deep RL)在 Atari 等游戏上取得了很大成功,但在图像处理领域,大多方法只对“整张图”做全局操作,例如全局裁剪、全局色彩调整等,难以应对需要“逐像素/局部区域精细操作”的任务,如去噪、修复、局部色彩增强等。
如何在像素级别引入强化学习? 作者提出一个新设定:pixelRL(reinforcement learning with pixel-wise rewards)。在这个设定中,每个像素都是一个智能体(agent),通过执行动作来修改对应像素值,并根据像素级奖励进行学习。问题在于:
- 图像中像素数量巨大(例如 1000×1000 就有 10⁶ 个 agent),
- 传统多智能体 RL 方法在如此规模下计算代价极高,难以直接应用。
仅考虑单个像素会忽略邻域关联性 图像里的像素并不是彼此独立的,噪声、纹理和结构都存在空间相关性。如果每个 agent 只关心自己像素的未来状态和奖励,很难学习到好的策略。因此作者还关注:
- 如何在 pixelRL 中有效地利用邻域像素的未来信息,
- 在保持可训练性的同时提升性能和稳定性。
可解释性的需求 传统 CNN 图像处理方法虽然性能强,但往往“黑箱”。作者希望通过 pixelRL 的方式,做到:
- 每一步、每个像素都能看到到底执行了什么操作(滤波/增亮/调饱和度等),
- 从而提升方法的可解释性与可视化分析能力。
本文提出的方法
问题建模
对于一幅包含 (N) 个像素的图像,每个像素 (i) 拥有一个 agent,其策略为πi(ai(t) ∣ si(t)) 其中 si(t) 是该像素在时间步t的状态(像素值或局部特征),ai(t) 是该像素采取的动作。
所有 agent 的目标是最大化所有像素平均总回报: $$ \pi^* = \arg\max_\pi \mathbb{E}_\pi \left[ \sum_{t=0}^{\infty} \gamma^t r^{(t)} \right],\quad r^{(t)} = \frac{1}{N}\sum_{i=1}^N r_i^{(t)} $$
环境状态就是当前整幅图像,动作执行后更新像素值,形成新的图像,再继续下一步迭代。
动作设计
- 输入:含噪灰度图或被文本覆盖的图像。
- 动作:每个时间步对像素执行以下 9 种动作之一:
- 方框滤波;
- 双边滤波(两种参数配置);
- 中值滤波;
- 高斯滤波(两种参数配置);
- 像素值 +1 / −1 微调;
- 保持不变。
- 方框滤波;
Reward Map Convolution(RMC)-考虑邻域未来状态的学习方法
若感受野为 1×1,各像素子问题相互独立,更新方式与原 A3C 类似,每个像素的回报: Ri(t) = ri(t) + γV(si(t + 1))
实际网络中,像素的策略和价值都依赖较大的空间感受野,意味着一个像素的动作会影响邻域像素的后续状态与价值。为此作者提出: Ri(t) = ri(t) + γ∑j ∈ 𝒩(i)wi − jV(sj(t + 1)) 其中wj是一个可学习的卷积核,表示在计算像素i的回报时,邻域像素j 的价值被赋予的权重。
在多步回报情形下,可以写成对奖励图和价值图进行多次卷积: R(t) = r(t) + γ w * r(t + 1) + ⋯ + γnwn * V(s(t + n))
训练时同时对策略网络、价值网络和卷积核w 进行梯度更新,形成“奖励图卷积”机制。
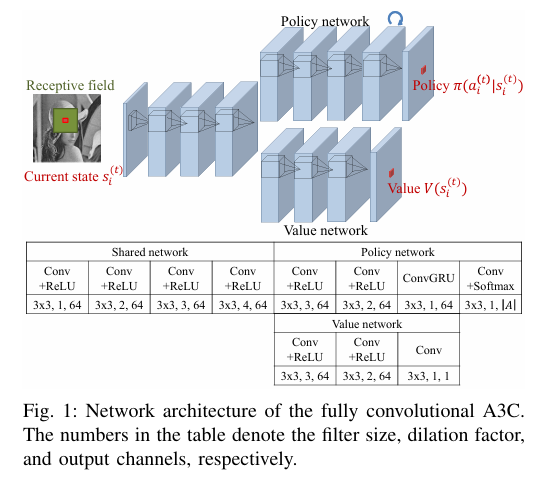
利用 FCN 解决“海量 agent”问题:Fully Convolutional A3C
直观做法是给每个像素配一个独立网络,显然不现实。作者采用全卷积网络(FCN):
- 所有像素共享同一套卷积参数,
- 在空间维度上并行计算每个位置的策略和价值。
阅读总结
创新点总结
- 把深度强化学习从“整图操作”扩展到“像素级多智能体”的设定,是本文最核心的概念创新。
- 通过 FCN + 参数共享,优雅地解决了“海量 agent”带来的计算和存储问题;
- 提出 Reward Map Convolution,把“考虑邻域未来回报”的思想变成一个可学习的 2D 卷积核,既符合图像的空间结构,又很好地融入了 A3C 框架。
- 利用固定、可解释的动作集(经典滤波、线性调色),在多个图像处理任务上达到接近甚至超越 SOTA 的表现,同时保留了强可解释性。
方法优势
适合目标函数难以微分的场景: 像显著性驱动编辑任务中,显著性是由外部算法算出的,不太方便写成端到端可微分的损失函数,而 PixelRL 只需要能算出“奖励”,不要求可微,这是 RL 的天然优势。
多步、逐像素“修图流程”的建模能力: 与一次前向的 CNN 不同,PixelRL 更像在模拟一个专业修图师的操作流程:先强滤波去噪,再小步微调;先提升目标区域亮度和饱和度,再降低背景对比度等。文中的可视化结果很好地体现了这种“过程感”。
可解释性强:每个像素、每个时间步到底执行了哪种滤波或调色操作都能可视化,对于需要安全性与可解释性的领域(如医学图像、自动驾驶感知等)具有潜在价值。